
Introduction
This is a follow-up to one of last month’s posts that contained some images of randomly-generated “lozenge tilings.” The focus here is not on the tilings themselves, but on the perfectly random sampling technique due to Propp and Wilson known as “coupling from the past” (see references below) that was used to generate them. As is often the case here, I don’t have any new mathematics to contribute; the objective of this post is just to go beyond the pseudo-code descriptions of the technique in most of the literature, and provide working Python code with a couple of different example applications.
The basic problem is this: suppose that we want to sample from some probability distribution 

For example, consider shuffling a deck of cards using the following iterative procedure: select a random adjacent pair of cards, and flip a coin to decide whether to put them in ascending or descending order (assuming any convenient total ordering, e.g. first by rank, then by suit alphabetically). Repeat for some “large” number of iterations.
There are two problems with this approach:
- It’s approximate; the longer we iterate the chain, the closer we get to the steady state distribution… but (usually) no matter when we stop, the distribution of the resulting state is never exactly
- How many iterations are enough? For many Markov chains, the mixing time may be difficult to analyze or even estimate.
Coupling from the past
Coupling from the past can be used to address both of these problems. For a surprisingly large class of applications, it is possible to sample exactly from the stationary distribution of a chain, by iterating multiple realizations of the chain until they are “coupled,” without needing to know ahead of time when to stop.
First, suppose that we can express the random state transition behavior of the chain using a fixed, deterministic function 

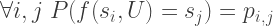
In other words, given a current state 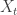
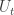

Now consider a single infinite sequence of random draws 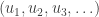
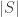
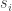
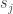


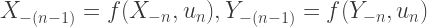
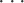

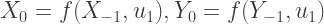
(Notice how the more random draws we generate, the farther back in time they are used. More on this shortly.)
A key observation is that if 
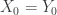
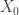
But what if all initial states don’t end at the same final state? This is where the single source of randomness is key: we can simply look farther back in the past, say 

Monotone coupling
So all we need to do to perfectly sample from the stationary distribution is
- Choose a sufficiently large
- Run
- As long as the final state
), generate additional random draws accordingly, and go back to step 2.
This doesn’t seem very helpful, since step 2 requires enumerating elements of the typically enormous state space. Fortunately, in many cases, including both lozenge tiling and card shuffling, it is possible to simplify the procedure by imposing a partial order 

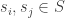

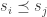
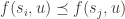
Then instead of running the chain for all possible initial states, we can just run two chains, starting with the minimum and maximum elements in the partial order. If those two chains are coupled by time zero, then they will also “squeeze” any other initial state into the same coupling.
Following is the resulting Python implementation:
import random
def monotone_cftp(mc):
"""Return stationary distribution sample using monotone CFTP."""
updates = [mc.random_update()]
while True:
s0, s1 = mc.min_max()
for u in updates:
s0.update(u)
s1.update(u)
if s0 == s1:
break
updates = [mc.random_update()
for k in range(len(updates) + 1)] + updates
return s0
Sort of like the Fisher-Yates shuffle, this is one of those algorithms that is potentially easy to implement incorrectly. In particular, note that the list of “updates,” which is traversed in order during iteration of the two chains, is prepended with additional blocks of random draws as needed to start farther back in the past. The figure below shows the resulting behavior, mapping each output of the random number generator to the time at which it is used to update the chains.

Random draws in the order they are generated, vs. the order in which they are used in state transitions.
Coming back once again to the card shuffling example, the code below uses coupling from the past with random adjacent transpositions to generate an exactly uniform random permutation 
class Shuffle:
def __init__(self, n, descending=False):
self.p = list(range(n))
if descending:
self.p.reverse()
def min_max(self):
n = len(self.p)
return Shuffle(n, False), Shuffle(n, True)
def __eq__(self, other):
return self.p == other.p
def random_update(self):
return (random.randint(0, len(self.p) - 2),
random.randint(0, 1))
def update(self, u):
k, c = u
if (c == 1) != (self.p[k] < self.p[k + 1]):
self.p[k], self.p[k + 1] = self.p[k + 1], self.p[k]
print(monotone_cftp(Shuffle(52)).p)
The minimum and maximum elements of the partial order are the identity and reversal permutations, as might be expected; but it’s an interesting puzzle to determine the actual partial order that these random adjacent transpositions preserve. Consider, for example, a similar process where we select a random adjacent pair of cards, then flip a coin to decide whether to swap them or not (vs. whether to put them in ascending or descending order). This process has the same uniform stationary distribution, but won’t work when applied to monotone coupling from the past.
Re-generating vs. storing random draws
One final note: although the above implementation is relatively easy to read, it may be prohibitively expensive to store all of the random draws as they are generated. The slightly more complex implementation below is identical in output behavior, but is more space-efficient by only storing “markers” in the random stream, re-generating the draws themselves as needed when looking farther back into the past.
import random
def monotone_cftp(mc):
"""Return stationary distribution sample using monotone CFTP."""
updates = [(random.getstate(), 1)]
while True:
s0, s1 = mc.min_max()
rng_next = None
for rng, steps in updates:
random.setstate(rng)
for t in range(steps):
u = mc.random_update()
s0.update(u)
s1.update(u)
if rng_next is None:
rng_next = random.getstate()
if s0 == s1:
break
updates.insert(0, (rng_next, 2 ** len(updates)))
random.setstate(rng_next)
return s0
References:
- Propp, J. and Wilson, D., Exact Sampling with Coupled Markov Chains and Applications to Statistical Mechanics, Random Structures and Algorithms, 9 1996, p. 223-252 [PDF]
- Wilson, D., Mixing times of lozenge tiling and card shuffling Markov chains, Annals of Applied Probability, 14(1) 2004, p. 274-325 [PDF]

Thanks for this nice post and the code.
I have a question here: in line 15/16 of the code in your last section “Re-generating vs. storing random draws”,
if rng_next is None:
rng_next = random.getstate()
I think the code can be simplified by deleting these two lines and replace the “rng_next” in line 19 by a “random.getstate()”. Also I dont understan why line20 is added there, it seems to be redundant …
This is a good question, since those lines are critical but slightly subtle in ensuring the desired behavior of the random draws. First, note that lines 15-16 are really only important *after* the first time through the while loop (that is, in the second and subsequent iterations). Consider the figure earlier in the post: for example, in the fourth iteration of the while loop, we generate the 8th through 15th random draws, at which point we want to preserve that state, so that we can generate the 16th random draw *later in a future iteration* (or after the function exits, see below). We have to preserve that state now, because we are going to “reset” the state to an earlier point so that we can *re-generate* draws 4 through 7, then reset it again to re-generate draws 2 and 3, then finally reset it again to re-generate draw 1.
So at the end of any iteration (other than the first), the random generator state has effectively only “consumed” a single random draw, although we have really consumed potentially many more than that. The last line 20 is just housekeeping to move the marker beyond all of those past draws.
You are right, my modification is incorrect in that it will always insert the same randomness at left. Thank you for your patient explanations.
Another question: would you mind if I republish this post and code (with modifications, of course) elsewhere?
The code is publicly licensed, so you’re welcome to do with it what you want. As far as the post itself, I suppose it depends on what is meant by “republishing:” linking or reblogging with appropriate citation, or quoting or paraphrasing relevant sections also with appropriate citation, etc., is fine.
Thanks, I have posted this cftp on lozenge tilings on my github project https://github.com/neozhaoliang/pywonderland
and the docs here
http://www.pywonderland.com
I have also added links to your post and give credit to your code.
Hi, I found that for a hexagon of fixed size, the program often terminates after a fixed number of steps. For example for a 10x10x10 hexagon, it usually takes 8388584 steps to stop (sometimes 4194281 steps). I checked it on several computers and this phenomena happened on all of them. May be this is a problem with the rnd generator of Python, or there are something wrong in the implementation?
I.m sorry, I the hexagon size I tested is 20x20x20. One can expect that the steps are roughly about 1 +2 + 4 + .. + 2^k = 2^{k+1} – 1 because we doubled the time backward in each round, but it should also have some fluctuations …
From the numbers that you provide, I am guessing you are counting the *total* number of calls to mc.random_update()? This will be a sum of (2^k-1) for k ranging from 1 to the number of iterations j through the while loop, for a total of 2^(j+1)-j-2.
The behavior you are seeing is simply the effect of *doubling* how far back in the past we start with each iteration, compared with the smaller *variance* in the distribution of how far we *have* to start the chain before coupling by time 0.
In other words, in the “next-to-last” iteration of the while loop, we start the chain at time -n=-(2^(j-1)-1), and advance to time zero, but the two bounding states haven’t coupled. So in the next (final) iteration, we start the chain farther back in time… but we didn’t really *have* to look so much farther back. Instead of roughly *doubling* the number of time steps in the past that we start, we could have just *incremented* the number of steps by a smaller fixed amount.
For example, let’s temporarily modify this increment to: updates.insert(0, (rng_next, 100)). In other words, instead of doubling, we always look 100 time steps farther back in the past with each iteration. If we do this, and repeatedly sample using monotone_cftp(), then we observe a “finer” variability in the distribution of number of iterations required… but at a cost of much slower execution time, since we are making a total number of updates that is quadratic in the mixing time, as opposed to a logarithmic multiplier with the doubling approach. (When testing this, I recommend using a much smaller chain, such as, say, Shuffle(26) described in the post, since Tiling((20,20,20)) will be prohibitively slow.)
Thanks for your clarification. I can understand the stuff now, so for a large example like the (20, 20, 20) hexagon, the expected total number of updates falls in the range between 2^23 – 22 – 2 = 8388584 and 2^22 – 21 -2 = 4914281, and its variance is comparatively small with this range, so we “tend to” observe the same number of updates, right?
Correct.