
“All models are wrong, but some are useful.” George E. P. Box
Last week I saw a clever short video titled, “Why the other line is likely to move faster.” It explains, among other things, why it often seems that no matter what checkout line you choose while doing your holiday shopping, you notice that another line is moving faster than yours. The video generated some interesting discussion, at least on Reddit and Slashdot where I bothered to look.
(Unfortunately, the title of the related Slashdot submission was, “Scientifically, You Are Likely In the Slowest Line.” This is not just misleading, it is simply false. As several commenters point out, the argument presented in the video is the weaker statement that “you are likely not in the fastest line.”)
The focus of this post, however, is on another observation in the video, and the corresponding online discussion. In the first part of the video, the Engineer Guy notes that there are (at least) two approaches to serving customers with multiple servers. The first approach, common in grocery stores, is to have a separate line, or queue, of customers for each server. The second approach, used at airport ticket counters, banks, etc., is to have a single queue of customers, with the person at the front of the queue waiting for the next available server.
The interesting observation made in the video is that the latter approach is much more efficient than the former: “… for 3 cashiers, it’s about 3 times faster than having a single line for each cashier.” From some of the comments, this seems to be “common knowledge” from queuing theory, and businesses that still have separate lines should apparently open an operations research textbook and get with the times.
I am not so sure. I am not an expert in queuing theory; even my last stochastic processes course was 12 years ago. So as an exercise, I wrote a series of simple discrete event simulations of this process to see what happens. For a specific example, let us assume that there are three cashiers as in the video. Customers arrive with exponentially distributed inter-arrival times at the average rate of one every two minutes. Each cashier serves a customer in an average time of five minutes, also exponentially distributed. In each of the two queuing approaches described above, what is the average time that a customer must wait in line? (This is the same setup used for a puzzle found here.)
Before getting to the simulation results, we can compute analytically what the average waiting times should be in both cases. (Actually, this is in part why we assume that arrival and service times are exponentially distributed, so that the problem is analytically tractable.) First, with three separate queues, the average waiting time is:

where 
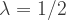
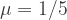
With a single queue feeding all three cashiers, the average waiting time is:

![P_0=\frac{1}{[ \sum\limits_{k=0}^{s-1} \frac{1}{k!}(\frac{\lambda}{\mu})^k] + \frac{1}{s!}(\frac{\lambda}{\mu})^s \frac{s\mu}{s\mu-\lambda}}](https://s0.wp.com/latex.php?latex=P_0%3D%5Cfrac%7B1%7D%7B%5B+%5Csum%5Climits_%7Bk%3D0%7D%5E%7Bs-1%7D+%5Cfrac%7B1%7D%7Bk%21%7D%28%5Cfrac%7B%5Clambda%7D%7B%5Cmu%7D%29%5Ek%5D+%2B+%5Cfrac%7B1%7D%7Bs%21%7D%28%5Cfrac%7B%5Clambda%7D%7B%5Cmu%7D%29%5Es+%5Cfrac%7Bs%5Cmu%7D%7Bs%5Cmu-%5Clambda%7D%7D&bg=ffffff&fg=333333&s=2&c=20201002)
This all matches up reasonably well with the threefold improvement mentioned in the video. And when I ran the simulation of the single queue case, I also saw an average waiting time of about 7.12 minutes. Everything makes sense so far.
However, when I ran the simulation with three separate queues, the average waiting time was only 7.77 minutes, nowhere near the predicted 25 minutes. What was going on?
It turned out that my simulation attributed more intelligence to the customers than is assumed in the above analysis. In my first draft of the multi-queue simulation, as each customer arrived ready to checkout, he entered the queue that currently had the fewest number of customers. In this case, the resulting behavior is not significantly worse than the single queue approach, in neither mean nor variance. When I modified the simulation so that each customer entered a randomly selected queue, the average waiting time jumped to 24.49 minutes as originally expected. (Edit 2020-12-31: Python code for these two simulation variants is available on GitHub.)
Who does this? Who approaches the front of the store with a full cart and just rolls a die to determine which line to enter? Of course, queue length is not the only factor to consider: customers also gain some information about potential waiting times by observing the number of items in others’ carts, there are express lanes with different distributions of service times, etc. Adding any of these factors to the model makes analysis more difficult, usually prohibiting closed form solutions like those above. (For example, I suspect, but am not sure, that even my original “enter the shortest queue” process does not have a clean analytical solution.)
I think the point here is that the grocery stores and other businesses with multiple queues are not necessarily missing out on a better approach. The mathematical models that admit clean solutions are only useful to the extent that they capture the relevant characteristics of the system being modeled. A model stops being useful when it fails to capture even modest intelligence of customers; or the space and logistics required for one long, possibly serpentine line of grocery carts; or the psychological effects of customers seeing exactly the same number of people, not in several smaller lines, but one long line, etc.
Finally, some mathematical musings: first, as mentioned above, is there a simple analytical expression for the average waiting time of the “shortest queue” process above? I suspect there is not. Also, what about selecting a queue at random? In the example above, I can certainly see how the average wait is 25 minutes if there are not only three separate queues, but three separate customer arrival processes, each with an average inter-arrival time of six minutes, for an aggregate arrival rate of one every two minutes. I suspect that the random queue selection above may be equivalent to this in the sense that it yields the same distribution of waiting times. Simulation bears this out, but I am not sure if things work out the same analytically.

Another thing is that people move around. If I estimate that I’ll get to the cashier faster on another line than on this line, I may move to the end of the other line.
Good point. This problem has received sufficient attention that there are reasonably standard names for these various refinements to the model: jockeying (the “moving around” that you mention), balking (seeing a long line and deciding not to bother), reneging (giving up after standing in line for too long), etc.
I was directed to a good paper that surveys many results, confirms my suspicion that exact analysis of the shortest queue case is intractable, yet provides some bounds and approximations:
http://www.jstor.org/stable/3213954
I’m convinced.
Just stumbled upon this as I was looking into queuing theory. I liked the fact your did a simulation model to test out the scenarios, and I think you are correct in pointing out that there is a human factor in picking the “right line” (i.e. what they think will be the shortest line).
However, if you want to take out or add more cashiers (i.e. breaks or shift changes) then having 1 line & multiple cashiers optimizes the wait for all customers. That is, taking away or adding cashiers affects all customers equally, versus affecting a few who wait in a line that ends up shutting down.
Also, keep in mind the scenario where customer’s don’t have any visibility on the length of the lines, such as in wait lists for surgeons. Surgeon could have a 1 year wait list, whereas Surgeon B could have none. If both of them are equally capable, than patients waiting for Surgeon A are waiting unnecessarily long. Again, one master list for the same product/service would be more ideal.
I’ve never seen a line be “shut down” with customers still in it, unless they opened the line next to it and shifted all the customers over — in which case, the next person in line gets served immediately, often while the breaking cashier finishes checking the current customer. It would be terrible customer service to just shut down a line with customers waiting, so instead they just shut it down to new customers.
However, you are right that in a cashier change, customers often end up waiting longer. However, when modeling these queues, delays seem to be generic, and would thus include a cashier change, which is often faster in real life than many other types of line delay.
Queue length is nowhere near as important as queue speed. The fastest queue is the one with the cashier who scans items and packs bags the most quickly. Avoid teenage male cashiers as they are slow scanners and terrible bag-packers; go for the queue with the cahier who is a female uni student and who’s register is going beepbeepbeepbeepbeep very quickly as she scans with super efficiency.
I thought the point of the single queue was to minimize the maximum wait time to minimize dissatisfied customers.
Not really– since the customer service times are exponentially distributed, they are unbounded, so there *isn’t* a maximum wait time.
From a customer’s point of view: I see a few cashiers, each with its own queue, and there are only 3 to 5 persons in the queue. I join the shortest queue. Sometimes it happens that a cashier has a few very short consecutive jobs, and empties the queue. Now, a few people at the end of the other queues quickly move to that empty queue and I still wait because I’m close to the head of my queue and didn’t change queue. I’m annoyed because this behaviour breaks the FIFO principle and this only happens in a multi-queue multi-service scenario. A single queue however will preserve the FIFO principle, and I can use that time for myself and not assessing all the time which is the quickest queue, etc.
Your post is indeed insightful. Curious may I know how did you build your simulation for a MQMS (multi queue multi server system?
I used a simple event-driven simulation framework that I had written in MATLAB, with events for (1) each new customer arrival and each server’s (2) beginning and (3) ending serving its current customer. (I actually did this twice, the second time in Python, as part of a performance comparison analysis for work.)
No, you’ve missed an important factor of customer experience: Averages are not what your customer experiences. What is the distribution of wait times? You should see a greater variability of wait times for the customers in the three queue/three servers model versus the one queue/three servers model.
The intuitive way to think about this is when you are next in line (three queue model) and the person in front of you has a gagillion items, 53 coupons and is writing a check. You sit there waiting for ten minutes while the other lines are moving at a more regular clip. In this example, the extra time that one customer takes to be processed is added to everyone’s time in that queue only — the customers in the other queues get a free pass. In the one queue model, the extra time is shared across the whole line, but less noticeably, because the other two servers are still processing normally.
You may have missed the following from the original post: when customers enter “the queue that currently had the fewest number of customers… the resulting behavior is not significantly worse than the single queue approach, in neither mean nor variance [emphasis added].” Using the specific setup described in the post, the standard deviation for the single-queue wait time is about 9.48 minutes; compare this with just 10.85 minutes for the shortest-of-3-queues, and 29.28 minutes for the pick-a-random-one-of-3-queues.
This plot shows the (lack of) difference more vividly, showing the entire distribution of wait times for all three cases, over a simulated 6-months’ worth of 16-hour days. The single-queue and shortest-queue cases are difficult to distinguish, because they just aren’t that different. The *random* queue, however, has significantly worse behavior.
One queue, multiple checkouts is the only way to go because it is fair to all. That results in ‘First come first served’ which is the way it should be, for those of us who have good manners that is. Why should a customer wait longer than someone who queued later than they did but somehow got into a faster line. Only those with bad manners who do not like to wait their turn and would rather a free for all push and shove system would argue against this.
Strongly agree with this comment!
Hi! Do you have a reference book with the detailed derivation of the relation that is visible after your sentence “With a single queue feeding all three cashiers, the average waiting time is:”. Thx for your answer!
This is referred to as a M/M/c queue; a search for “M/M/c queue waiting time” yields several links to course notes that work through the derivation of these formulas.
I’m looking for the proof since 3 years on the internet and in textbooks. I have found the result a lot of time but not the VERY detailed steps of the formula derivation (sad!). But thanks anyway.
I am not sure if you are monitoring this anymore…anyway, I found your analysis to be very useful, but I do have a question: I am attempting to replicate your result where the customer chooses the shortest queue, and am consistently getting 8.54-8.60 minutes average wait time (you got 7.77). I am not sure why the discrepancy, but one thing that you don’t mention is what happens when there is more than one line that is shortest (i.e., lines are of equal length, which happens often). I assumed that the customer will randomly choose a line (out of the shortest ones), without knowledge of which line will actually result in being served sooner. I’m thinking that you probably did the same, since if customers are somehow always able to choose the line in which they will be served soonest, the result should be the same as the MM3 (7.12), but I thought that I would check.
Although 8.6 minutes seems a bit long, after revisiting this I think 7.8 minutes is also a bit short :). That is, the large variance of customer waiting time means that we need to simulate a lot of customers to accurately estimate the mean, and my initial implementation in MATLAB was slow enough that I only sampled a few “months” worth of customers.
So I re-wrote the simulation in Python, and cranked up the simulation time (about 2.4 million customers), so that a more accurate estimate is around 8.1-8.2 minutes. See code here if you’d like to compare; lines 14-15 of test_queue.py pick the shortest queue, breaking ties by lowest index.