
Introduction
The “Bayesian/frequentist” coin puzzle discussed in the last couple of posts was really just an offshoot of some thoughts I have been mulling over about Reddit’s current default approach to ranking user comments on a post, based on the number of upvotes and downvotes each comment receives. (Or more generally, the problem of ranking a collection of any items, whether comments, or consumer products, etc., based on varying numbers of “like/dislike” votes.) Instead of trying to estimate the bias of a coin based on the observed number of heads and tails flipped, here each comment is like a coin, and each upvote (or downvote) is like an observation of a coin flip coming up heads (or tails).
If we assume that each comment has some fixed– but unknown– probability 

A natural first idea might be to “score” each comment using the maximum likelihood estimate

and sort the comments by this score. But this tends to unfairly compare comments with very different numbers of total votes; e.g., should a comment with votes 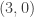

Wilson Score Interval
Evan Miller’s “How Not To Sort By Average Rating” does a good job of presenting this and other approaches, eventually arguing for sorting by the lower bound of the Wilson score interval, which is what Reddit currently does. Briefly, the Wilson score interval is a confidence interval intended to “cover” (i.e., contain) the true— but unknown– value
Reddit’s use of this scheme has evolved slightly over time, initially computing a 70% confidence interval, but then changing to the current wider 80% confidence interval, having the effect of imposing a slightly greater penalty on comments with fewer total votes. This “fine-tuning” of the scoring algorithm raises the question whether there might not be a more natural method for ranking user comments, that does not require this sort of knob-turning.
A Bayesian Alternative
Last year, James Neufeld proposed the interesting idea of sampling a random score for each comment by drawing from a corresponding beta distribution with parameters

The idea is that this beta distribution is a natural way to express our uncertainty about the “true” value

Probability density of beta distribution with parameters (30+1,10+1).
A key point is that every user does not necessarily see the comments for a post in the same order. Each time the post is viewed, the comments are re-scored by new random draws from the corresponding beta distributions, and sorted accordingly. As a comment receives more and more upvotes and/or downvotes, it will “settle in” to a particular position among other comments… but comments with few votes, or even strongly downvoted comments, will still have some chance of appearing near the top of any particular user’s view of the page.
I really like this idea, but the non-deterministic ordering of comments presented to different users may be seen as a drawback. Can we fix this?
Sorting by Expected Rank
I can think of two natural deterministic modifications of this approach. The first is to sort comments by their expected ranking using the random scoring described above. In other words, for each comment, compute the expected number of other comments that would appear higher than it on one of Neufeld’s randomly generated pages, and sort the comments by this expected value.
Although this method “fixes” the non-determinism of the original, unfortunately it suffers from a different undesirable property: the relative ranking of two comments may be affected by the presence or absence of other comments on the same post. For example, consider the two comments identified by their upvote/downvote counts 
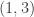



Pairwise comparisons
Which brings me, finally, to my initial idea for the following second alternative: sort the comments on a post according to the order relation

where

More intuitively, we are simply ranking one comment higher than another if it is more likely than not to appear higher using Neufeld’s randomized ranking.
Note one interesting property of this approach that distinguishes it from all of the other methods mentioned so far: it does not involve assigning a real-valued “score” to each individual comment (and subsequently sorting by that score). This is certainly possible in principle (see below), but as currently specified we can only compare two comments by performing a calculation involving parameters of both in a complex way.
Open Questions
Unfortunately, there are quite a few holes to be patched up with this method, and I am hoping that someone can shed some light on how to address these. First, the strict order defined above is not quite a total order, since there are some pairs of distinct comments where one comment’s randomized score is equally likely to be higher or lower than the other. For example, all of the comments of the form 
But there are other more interesting pairs of incomparable comments. For example, consider 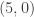



This brings us to the next open question: is this order relation transitive (in other words, is it even a partial order)? I have been unable to prove this, only verify it computationally among comments with bounded numbers of votes.
The final problem is a more practical one: how efficiently can this order relation be computed? Evaluating the probability that one beta-distributed random variable exceeds another involves a double integral that “simplifies” to an expression involving factorials and a hypergeometric function of the numbers of upvotes and downvotes. If you want to experiment, following is Python code using the mpmath library to compute the probability 
from mpmath import fac, hyp3f2
def prob_greater(u1, d1, u2, d2):
return (hyp3f2(-d2, u2 + 1, u1 + u2 + 2, u2 + 2, u1 + u2 + d1 + 3, 1) *
fac(u1 + u2 + 1) / (fac(u1) * fac(u2)) *
fac(u1 + d1 + 1) * fac(u2 + d2 + 1) /
((u2 + 1) * fac(d2) * fac(u1 + u2 + d1 + 2)))
print(prob_greater(5, 0, 13, 1))
John Cook has written a couple of interesting papers on this, in the medical context of evaluating clinical trials. This one discusses various approximations, and this one presents exact formulas and recurrences for some special cases. The problem of computing the actual probability seems daunting… but perhaps it is a simpler problem in this case to not actually compute the value, but just determine whether it is greater than 1/2 or not?
In summary, I think these difficulties can be rolled up into the following more abstract statement of the problem: can we impose a “natural,” efficiently computable total order on the set of all beta distributions with positive integer parameters, that looks something like the order relation described above?

Do you think that there could be ranking system that used the history of an item. This would be useful when an item must be voted with knowledge of its current rank.
Certainly there could be, and to an extent there already is; see, for example, the “hot” ranking, which incorporates not only upvotes/downvotes but also the age of an item. An even more complex algorithm could take into account not only the age of the item itself, but also the time history of the *votes*, so that, for example, recent votes on an old item might be weighed more heavily than older votes.
Pingback: How not to sort by average rating, revisited | EFavDB
Pingback: A number concatenation problem | Possibly Wrong
Isn’t the solution described in https://towardsdatascience.com/bayesian-ranking-system-77818e63b57b a better solution?
Thanks for the link. In my opinion, no, for several reasons. First, it’s not necessary that “we’ll need some algorithm to convert to a scalar for ranking.” All that is needed is the weaker requirement of an order relation to compare pairs of items being ranked.
Second, why 95% confidence? Why not 90%, or 85%, or 80%? Or why not the lower bound of a highest-density interval (again at a specified significance) instead of just a quantile? Granted, for this specific set of five beta distributions, the resulting ranking is unchanged, but in general the ranking is affected by that choice of confidence level (something Reddit “tuned” over the years)– a choice that seems like an arbitrary “knob” that requires turning, as described in this post.
Third, messing with the prior (from uniform B(1,1) to B(11,11)) also seems like arbitrary knob-turning. Even if we felt this prior was justified for movies, it might not translate to other domains, like comments in a discussion forum (are “average” Reddit comments also expected to be more common than really good or really bad comments?), etc. Indeed, if anything, the specific pair of movies motivating this fine-tuning (A’s 60-40 vs. B’s 6-1) feels to me like A should be ranked lower than B, because of the stronger evidence for its mediocrity.