
This is just a quick follow-up to capture my notes on an approach to solving the following problem from the last post:
Problem: Suppose you and 
After all players have taken a turn, the player with the highest score (not exceeding 1) wins the game. You get to go first– what should your strategy be, and what are your chances of winning?
Solution: Suppose that our strategy is to continue to spin until our score exceeds some target value 
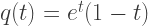
To see this, partition the successful outcomes by the number 
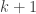
![(t, 1]](https://s0.wp.com/latex.php?latex=%28t%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
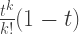
(which may be shown by induction, or see also here and here), and the result follows from the Taylor series expansion for 
At this point, we can express the overall probability of winning using strategy

Intuitively, we must:
- Safely reach a score in the interval
; and
- For each such score
, reached with uniform density
, each of the remaining
The optimal strategy consists of choosing a target score 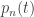
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

The idea is that we are choosing a target score
Handing the problem over to the computer, the following table shows the optimal target score and corresponding probability of winning for the first few values of

Optimal target score (red) and corresponding probability of winning (blue), vs. number of additional players.
One final note: how does this translate into an optimal strategy for the players after the first? At any point in the game, the current player has some number
[Edit: Following is Python code using mpmath that implements the equations above.]
import mpmath
def q(t):
return mpmath.exp(t) * (1 - t)
def p_stop(t, n):
return (1 - q(t)) ** n
def p_spin(t, n):
return mpmath.quad(lambda s: p_stop(s, n), [t, 1])
def t_opt(n):
return mpmath.findroot(
lambda t: p_spin(t, n) - p_stop(t, n), [0, 1], solver='ridder')
def p_win(t, n):
return q(t) / (1 - t) * p_spin(t, n)
if __name__ == '__main__':
for n in range(11):
t = float(t_opt(n))
p = float(p_win(t, n))
print('{:4} {:.9f} {:.9f}'.format(n, t, p))

What are the actual values from your plot? And how accurate do you think you got them?
I updated the post to include some Python code for performing the calculations (although I actually used Mathematica to do the integration, generate the plot, etc.). Here is a pastebin showing the output.
I should probably clarify the “no closed form” comment in the original post, because things aren’t quite as bad as they might initially seem. First, the expression for p_n(t), as well as the definite integral probability of “spinning one more time” on the lhs of the equation above, *can* be computed exactly. Or more precisely, once we have *found* a particular target score t, that integral expands to a polynomial in t and e^t. (Note that I cheated in the Python code, however, since it just uses quadrature numeric integration, but in Mathematica we can do it exactly, or even without the symbolic manipulation, we could still evaluate the integral using a binomial summation, and a recurrence relation for some incomplete gamma functions under the hood.)
It’s only the *root-finding*, equating the lhs and rhs and solving to *find* the critical score t, that does *not* have a closed form and requires a numeric approximation… but this can be done to arbitrary precision using standard techniques, even Newton’s method which requires a derivative.