
Introduction
A common development approach in MATLAB is to:
- Write MATLAB code until it’s unacceptably slow.
- Replace the slowest code with a C++ implementation called via MATLAB’s MEX interface.
- Goto step 1.
Regression testing the faster MEX implementation against the slower original MATLAB can be difficult. Even a seemingly line-for-line, “direct” translation from MATLAB to C++, when provided with exactly the same numeric inputs, executed on the same machine, with the same default floating-point rounding mode, can still yield drastically different output. How does this happen?
There are three primary causes of such differences, none of them easy to fix. The purpose of this post is just to describe these causes, focusing on one in particular that I learned occurs more frequently than I realized.
1. The butterfly effect
This is where the drastically different results typically come from. Even if the inputs to the MATLAB and MEX implementations are identical, suppose that just one intermediate calculation yields even the smallest possible difference in its result… and is followed by a long sequence of further calculations using that result. That small initial difference can be greatly magnified in the final output, due to cumulative effects of rounding error. For example:
x = 0.1;
for k in 1:100
x = 4 * (1 - x);
end
% x == 0.37244749676375793
double x = 0.10000000000000002;
for (int k = 1; k <= 100; ++k) {
x = 4 * (1 - x);
}
// x == 0.5453779481420313
This example is only contrived in its simplicity, exaggerating the “speed” of divergence with just a few hundred floating-point operations. Consider a more realistic, more complex Monte Carlo simulation of, say, an aircraft autopilot maneuvering in response to simulated sensor inputs. In a particular Monte Carlo iteration, the original MATLAB implementation might successfully dampen a severe Dutch roll, while the MEX version might result in a crash (of the aircraft, I mean).
Of course, for this divergence of behavior to occur at all, there must be that first difference in the result of an intermediate calculation. So this “butterfly effect” really is just an effect— it’s not a cause at all, just a magnified symptom of the two real causes, described below.
2. Compiler non-determinism
As far as I know, the MATLAB interpreter is pretty well-behaved and predictable, in the sense that MATLAB source code explicitly specifies the order of arithmetic operations, and the precision with which they are executed. A C++ compiler, on the other hand, has a lot of freedom in how it translates source code into the corresponding sequence of arithmetic operations… and possibly even the precision with which they are executed.
Even if we assume that all operations are carried out in double precision, order of operations can matter; the problem is that this order is not explicitly controlled by the C++ source code being compiled (edit: at least for some speed-optimizing compiler settings). For example, when a compiler encounters the statement double x = a+b+c;, it could emit code to effectively calculate 
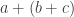
(0.1 + 0.2) + 0.3 == 0.1 + (0.2 + 0.3) % this is false
Worse, explicit parentheses in the source code may help, but it doesn’t have to.
Another possible problem is intermediate precision. For example, in the process of computing 
3. Transcendental functions
So suppose that we are comparing the results of MATLAB and C++ implementations of the same algorithm. We have verified that the numeric inputs are identical, and we have also somehow verified that the arithmetic operations specified by the algorithm are executed in the same order, all in double precision, in both implementations. Yet the output still differs between the two.
Another possible– in fact likely– cause of such differences is in the implementation of transcendental functions such as sin, cos, atan2, exp, etc., which are not required by IEEE-754-2008 to be correctly rounded due to the table maker’s dilemma. For example, following is the first actual instance of this problem that I encountered years ago, reproduced here in MATLAB R2017a (on my Windows laptop):
x = 193513.887169782; y = 44414.97148164646; atan2(y, x) == 0.2256108075334872
while the corresponding C++ implementation (still called from MATLAB, built as a MEX function using Microsoft Visual Studio 2015) yields
#include <cmath> ... std::atan2(y, x) == 0.22561080753348722;
The two results differ by an ulp, with (in this case) the MATLAB version being correctly rounded.
(Rant: Note that both of the above values, despite actually being different, display as the same 0.225610807533487 in the MATLAB command window, which for some reason neglects to provide “round-trip” representations of its native floating-point data type. See here for a function that I find handy when troubleshooting issues like this.)
What I found surprising, after recently exploring this issue in more detail, is that the above example is not an edge case: the MATLAB and C++ cmath implementations of the trigonometric and exponential functions disagree quite frequently– and furthermore, the above example notwithstanding, the C++ implementation tends to be more accurate more of the time, significantly so in the case of atan2 and the exponential functions, as the following figure shows.

Probability of MATLAB/C++ differences in function evaluation for input randomly selected from the unit interval.
The setup: on my Windows laptop, with MATLAB R2017a and Microsoft Visual Studio 2015 (with code compiled from MATLAB as a MEX function with the provided default compiler configuration file), I compared each function’s output for 1 million randomly generated inputs– or pairs of inputs in the case of atan2— in the unit interval.
Of those 1 million inputs, I calculated how many yielded different output from MATLAB and C++, where the differences fell into 3 categories:
- Red indicates that MATLAB produced the correctly rounded result, with the exact value between the MATLAB and C++ outputs (i.e., both implementations had an error less than an ulp).
- Gray indicates that C++ produced the correctly rounded result, with both implementations having an error of less than an ulp.
- Blue indicates that C++ produced the correctly rounded result, between the exact value and the MATLAB output (i.e., MATLAB had an error greater than an ulp).
(A few additional notes on test setup: first, I used random inputs in the unit interval, instead of evenly-spaced values with domains specific to each function, to ensure testing all of the mantissa bits in the input, while still allowing some variation in the exponent. Second, I also tested addition, subtraction, multiplication, division, and square root, just for completeness, and verified that they agree exactly 100% of the time, as guaranteed by IEEE-754-2008… at least for one such operation in isolation, eliminating any compiler non-determinism mentioned earlier. And finally, I also tested against MEX-compiled C++ using MinGW-w64, with results identical to MSVC++.)
For most of these functions, the inputs where MATLAB and C++ differ are distributed across the entire unit interval. The two-argument form of the arctangent is particularly interesting. The following figure “zooms in” on the 16.9597% of the sample inputs that yielded different outputs, showing a scatterplot of those inputs using the same color coding as above. (The red, where MATLAB provides the correctly rounded result, is so infrequent it is barely visible in the summary bar chart.)

Scatterplot of points where MATLAB/C++ differ in evaluation of atan2(y,x), using the same color coding as above.
Conclusion
This might all seem rather grim. It certainly does seem hopeless to expect that a C++ translation of even modestly complex MATLAB code will preserve exact agreement of output for all inputs. (In fact, it’s even worse than this. Even the same MATLAB code, executed in the same version of MATLAB, but on two different machines with different architectures, will not necessarily produce identical results given identical inputs.)
But exact agreement between different implementations is rarely the “real” requirement. Recall the Monte Carlo simulation example described above. If we run, say, 1000 iterations of a simulation in MATLAB, and the same 1000 iterations with a MEX translation, it may be that iteration #137 yields different output in the two versions. But that should be okay… as long as the distribution over all 1000 outputs is the same– or sufficiently similar– in both cases.

A mutual acquaintance asked me about exactly this just yesterday, and I suspect that’s no coincidence. I pointed him to CppCon 2015: John Farrier “Demystifying Floating Point”, which I had just re-watched because it was recommended in that other CppCon video.
My initial thought was that Matlab may be less strict than C++ about associativity. This is where I think you’re mistaken in your article. Exactly because of the associativity problem you mentioned, a C++ compiler is not allowed choose an arbitrary evaluation order of
a + b + cfor floating point operands. The plus operator is left associative, so this expression is strictly equivalent to(a + b) + cand the compiler cannot (normally) pretend otherwise. The compiler is broken otherwise. In the C99 specification there’s a specific example about this (5.1.2.3-14), and I don’t expect C++ changed this.Side note: This demonstrates one major reason why I prefer C to C++. I wanted to verify this for myself from the standard. I don’t like having to trust some StackOverflow answer (for example). The C standard is relatively short (552 pages for C99), and I can generally find what I need to know. The C++11 standard is 1324 pages and monstrously complicated — and getting worse each time they make a new standard, such as with C++17 (~1647 pages). When you’re running into a tricky problem, you need to understand all the parts, which includes referencing the language specification. If anything, I’d give up on a number of C99’s features just to cut down on the size of that document, but the damage has already been done.
The infamous
-ffast-mathswitch for GCC and Clang relaxes the language standard and lets the compilers perform some transformations that are otherwise forbidden (particularly-fassociative-math). Presumably you’re not using this flag since you definitely shouldn’t.I didn’t know there was so much variation in the results of the transcendental functions. Until I read your article, I thought these were stricter. Now I’m currently convinced that’s the original source of the problem, exacerbated by the butterfly effect. I’d bet one of the few ways Matlab would play it loose with the standardized floating point operations is under vectorization, which is basically the only way to get decent performance from Matlab.
MinGW-w64 (unfortunately, IMHO) links against msvcrt.dll and probably directly uses most its trigonometric functions, so it’s not surprising it has the same results as MSVC++. This is essentially the same thing I discovered with qsort().
I wonder if MathWorks uses their own implementations of the transcendental functions rather than relying on their C++ compiler/runtime (or whatever they’re using). That would be the smart thing to do so that Matlab’s results would be uniform across different platforms. If this is true, then you were essentially testing Microsoft’s implementation against Matlab’s. If you ran the tests on Linux, where the C++ version of these functions would be ultimately supplied by glibc, I wonder how it would compare.
“The infamous -ffast-math switch for GCC and Clang relaxes the language standard and lets the compilers perform some transformations that are otherwise forbidden (particularly -fassociative-math). Presumably you’re not using this flag since you definitely shouldn’t.” Yep, this is actually what I was referring to (or /fp:fast in the case of MSVC++), which Dawson also discusses in the article linked in the post. It appears that /fp:precise is the default when building with MSVC++ from MATLAB with its “out of the box” MEX options… but this still allows more freedom than /fp:strict, and stricter doesn’t necessarily imply *more accurate* (more discussion on MSVC++ specifics here).
It isn’t clear to me why “you definitely shouldn’t [use /fp:fast]”? Dawson makes this point as well, which I agree with: for an arguably large majority of use cases (including much of the analysis of the sort motivating this post), the desirable property is not necessarily getting *exactly the same* answer [as the MATLAB code] down to the ulp, but getting a *sufficiently accurate* answer *more quickly*. Granted, the “sufficiently accurate” is in the eye of the beholder and specific to each use case, but we can do the numerical analysis to figure out what is acceptable for the task at hand.
“That would be the smart thing to do so that Matlab’s results would be uniform across different platforms.” Unfortunately, things are weirder than that. As noted near the end of the post, even the same MATLAB code, on two different machines with slightly different (ages of) architecture, both running Win64, can yield different results, suggesting that (1) MATLAB has some architecture-dependent switching, and thus (2) reproducing this analysis on another machine might yield interestingly different results.
Furthermore, MSVC++ on Win64 vs. Win32 are also different! And the different Win32 results appear to agree with the different MATLAB (Win64) results… although I have only spot-checked a small number of examples of this.
I didn’t mean in general
-ffast-mathshouldn’t be used, but that you shouldn’t use it in this situation where (it seemed) you were trying to match Matlab’s results in a line-by-line translation. The compiler would undo the care taken in the translation. It would also be inappropriate when you’ve manually planned out your floating point operations to keep alike magnitudes together, since the compiler would undo that planning as well (unaware of the expected magnitudes of the operands).When I wrote the raytracer with my intern, we were using
-ffast-mathfrom day one since I knew it wouldn’t matter. And, as you mentioned, it’s not even necessarily less precise, especially if the compiler employs fused multiply-add. As an exercise, we compared the output images between-ffast-mathenabled and disabled. They were subtly different — it was interesting to compute the difference in Gimp and stretch it out to be visible — but the difference was completely imperceptible to us.When adding multithreading, I had him disable
-ffast-mathjust for testing. The goal was to have bit-for-bit identical output before and after threading was added, and-ffast-mathwould make the results non-deterministic (different optimization decisions across different builds). Individual rays were computed entirely independently of one another, so if there was a difference under multithreading then there was a mistake in the code (race, etc.).Another place it would be appropriate is the physics engine for a single player game. The difference would probably be imperceptible to players. However, it may be inappropriate for multiplayer physics engines that need to synchronize their results over a network. Two different builds could diverge enough that it annoys players (rubber banding, misses that look like hits, etc.). That’s just something to measure and test.
In the past I’ve figured it’s good policy to leave it off for scientific computing. But the only way I can justify this is when either you’ve manually planned out your floating point operations, or you require deterministic output across builds. As you’ve shown, the latter doesn’t really work so well if you call transcendental functions (unless you implement them yourself). So your article, plus some recent thought, has changed my mind on this.
Oops! Sorry, I missed that sentence. That’s another thing to add to the list of mysterious Matlab quirks.
The Win32 version is probably using the old x87 ISA, working internally in 80-bit precision and using the fsin, fcos, etc. instructions. The Win64 version would only use the SSE2 (and later) ISA. So for floating point operations that’s basically running the code on two different CPU architectures.