
Introduction
During a recent vacation flight, my nephews had a couple of interesting puzzles to occupy them on the plane: Kanoodle and IQ Fit. In both cases, the objective is to arrange a set of colored pieces so that they exactly fill a rectangular grid, as in the following figure showing an example solution to the Kanoodle puzzle:

Example solution to Kanoodle puzzle.
The IQ Fit version uses a smaller 5-by-10 grid, and only 10 pieces instead of 12… but the pieces are three-dimensional, so that some of the spherical “vertices” of the pieces may poke down through the bottom of the tray. (For reference, following is Python code specifying the configurations of pieces for both puzzles.)
kanoodle = {
'Green': ((1, 1, 0), (1, 2, 0), (2, 2, 0), (2, 3, 0), (2, 4, 0)),
'Cyan': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (2, 3, 0), (3, 3, 0)),
'Purple': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (1, 4, 0)),
'Yellow': ((1, 1, 0), (1, 2, 0), (2, 2, 0), (3, 1, 0), (3, 2, 0)),
'Orange': ((1, 1, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0)),
'Blue': ((1, 2, 0), (2, 2, 0), (3, 2, 0), (4, 1, 0), (4, 2, 0)),
'Pink': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (1, 4, 0), (2, 3, 0)),
'Gray': ((1, 2, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0), (3, 2, 0)),
'Magenta': ((1, 1, 0), (1, 2, 0), (2, 2, 0), (2, 3, 0), (3, 3, 0)),
'Red': ((1, 1, 0), (1, 2, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0)),
'White': ((1, 1, 0), (2, 1, 0), (2, 2, 0)),
'LightGreen': ((1, 1, 0), (1, 2, 0), (2, 1, 0), (2, 2, 0))
}
iq_fit = {
'Green': ((1, 1, 0), (2, 1, 0), (2, 2, 0), (3, 1, 0),
(1, 1, -1), (2, 1, -1)),
'Magenta': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (2, 2, 0),
(2, 3, 0), (1, 1, -1)),
'Cyan': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (1, 4, 0),
(2, 2, 0), (1, 2, -1), (1, 3, -1)),
'LightGreen': ((1, 1, 0), (1, 2, 0), (2, 2, 0), (3, 1, 0),
(3, 2, 0), (3, 2, -1)),
'Blue': ((1, 4, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0), (2, 4, 0),
(2, 2, -1), (2, 4, -1)),
'Purple': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (2, 2, 0),
(1, 1, -1), (1, 3, -1)),
'Yellow': ((1, 1, 0), (1, 2, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0),
(2, 4, 0), (2, 4, -1)),
'Pink': ((1, 1, 0), (1, 2, 0), (1, 3, 0), (1, 4, 0), (2, 1, 0),
(2, 2, 0), (1, 2, -1)),
'Orange': ((1, 3, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0), (2, 4, 0),
(2, 1, -1), (2, 3, -1)),
'Red': ((1, 4, 0), (2, 1, 0), (2, 2, 0), (2, 3, 0), (2, 4, 0),
(2, 1, -1), (2, 4, -1))
}
A natural question to ask is: which puzzle is harder? For example, which puzzle has more possible solution configurations? Can we count them all? It turns out that we can, using Donald Knuth’s “Dancing Links” (DLX) algorithm (see references below). But the motivation for this post is to describe another interesting application of DLX: before attempting an exact count, we can first estimate the number of solutions, to determine whether it is even worth trying to enumerate them.
Exact Cover
The Kanoodle and IQ Fit puzzles are examples of the more general exact cover problem: given a matrix of 0s and 1s, does it have a set of rows containing exactly one 1 in each column? Many other problems may also be reduced to that of finding an exact cover: Sudoku, Langford sequences, and graph colorings are just a few examples.
Often the most interesting part of solving many of these problems is figuring out the transformation to an exact cover instance. That is, how do we construct a 0-1 matrix representing our problem, so that a set of rows containing exactly one 1 in each column corresponds to a solution to our problem? In the case of Kanoodle (and IQ Fit is similar), there are two “kinds” of columns: one column for each of the 12 puzzle pieces, and one column for each position in the 5-by-11 rectangular grid. Each row of the matrix represents a possible placement of one of the pieces, with a single 1 in the corresponding “piece” column, and additional 1s in the corresponding occupied “position” columns. A set of rows solving the exact cover problem will have exactly one row for each piece, oriented and positioned so that all of the grid positions are occupied by exactly one piece.
Considering all possible placements of all pieces, the Kanoodle puzzle has a total of 1789 rows and 67 columns, while the IQ Fit puzzle has 3440 rows and 60 columns. (David Austin wrote a great AMS Feature Column on this same topic, suggesting that the Kanoodle puzzle has 2222 rows; there are a couple of bugs in his implementation, however, yielding some extra invalid piece placements and some missing valid ones.)
Dancing Links (DLX)
Now that we have a matrix representing our exact cover problem, we can feed it to Knuth’s Dancing Links algorithm (referred to as DLX), which is essentially “just” a backtracking depth-first tree search for all possible solutions, but with a “doubly-doubly” linked list sparse matrix representation that allows very efficient undo operations. I won’t bother with details here, especially since Knuth’s paper is so readable.
My implementation is available in the usual location here, as well as on GitHub. There isn’t much there; the search algorithm itself follows Knuth’s pseudocode nearly verbatim, right down to the variable names.
There are quite a few DLX implementations in the wild already, but I ended up writing my own for several reasons. First, the matrix row and column identifiers should be of generic types; the “real” problem is rarely represented in terms of simple consecutive integer matrix indices. Second, it seemed reasonable to be able to construct the sparse matrix by adding 1s individually, in any order. Although the diagrams in Knuth’s paper suggest a nice “weaving loom” look to the data structure, there is no need to preserve any particular order relation on the rows or columns. Third, although I didn’t use it for this analysis, it was relatively simple to add support for “secondary,” or optional columns, which must be covered at most once, instead of exactly once. (As discussed in Knuth’s paper, the N queens problem is a natural example where this is handy.)
Estimating Tree Size
Finally, and most importantly, I wanted to try using the Monte Carlo sampling technique, mentioned briefly in Knuth’s DLX paper, to estimate the size of the search tree without actually exploring all of it. As Knuth puts it (see Reference (3) below):
Sometimes a backtrack program will run to completion in less than a second, while other applications seem to go on forever. The author once waited all night for the output from such a program, only to discover that the answers would not be forthcoming for about 1,000,000 centuries.
The sampling algorithm is pretty simple: take a random walk from the root of the tree to a leaf, at each step recording the (out-)degree 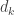

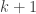
Furthermore, the expected value of the product 


This algorithm almost feels like cheating; we are trying to estimate the size of an entire tree, when there are whole chunks of it that we may never explore!
The following figure shows the result of 2 million such random paths through the Kanoodle DLX search tree. The blue points indicate the current running estimate of the total number of solutions– more precisely, the number of tree vertices at depth 12.

Monte Carlo estimate of number of Kanoodle solutions (blue), with actual number of solutions (red).
In this case, the couple of minutes needed to collect the random samples turned out to be longer than the 30 seconds to simply traverse the entire tree, yielding exactly 371,020 different solutions to the Kanoodle puzzle (shown in red above).
The IQ Fit puzzle was more interesting; the following figure again shows the running estimate (in blue) of the number of leaf vertices at depth 10 in the DLX search tree.

Monte Carlo estimate of number of IQ Fit solutions (blue), with actual number of depth 10 terminal vertices (red), and actual number of solutions (green).
Using this estimate of what turned out to be exactly 254,531,140 vertices at depth 10 (shown in red above), I expected to get an exact count via a full tree traversal in about 6 hours. However, just an hour and a half later, my program had already stopped, reporting that there were only 67,868,848 solutions (shown in green), about one-fourth what I expected. What was going on?
After further investigation, I realized that, unlike the Kanoodle puzzle, it is possible to arrange the three-dimensional IQ Fit pieces so that all 10 pieces fit into the grid… but with some spaces still left unfilled. These non-solution arrangements account for the remaining three-fourths of the leaf vertices at depth 10 in the tree.
References:
- Austin, D., Puzzling Over Exact Cover Problems, American Mathematical Society Feature Column, December 2009 (HTML)
- Knuth, D., Dancing Links, Millenial Perspectives in Computer Science, 2000, p. 187-214 (arXiv)
- Knuth, D., Estimating the efficiency of backtrack programs, Mathematics of Computation, 29 (1975), p. 121–136 (PDF)
![f : [n] \rightarrow [n]](https://s0.wp.com/latex.php?latex=f+%3A+%5Bn%5D+%5Crightarrow+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , not necessarily a bijection, that maximizes the probability of agreeing with a randomly chosen “solution” bijection in at least
, not necessarily a bijection, that maximizes the probability of agreeing with a randomly chosen “solution” bijection in at least  questions?
questions? of
of  , with the parts corresponding to the sizes of the classes of the
, with the parts corresponding to the sizes of the classes of the  . The number of parts in the partition indicates the number of distinct quiz answers. For example,
. The number of parts in the partition indicates the number of distinct quiz answers. For example,
 corresponds to a constant function, i.e., writing the same answer for all
corresponds to a constant function, i.e., writing the same answer for all 
 that exactly some subset
that exactly some subset ![S \subseteq [k]](https://s0.wp.com/latex.php?latex=S+%5Csubseteq+%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) of distinct answers is correct using
of distinct answers is correct using 

![T \subseteq [k]](https://s0.wp.com/latex.php?latex=T+%5Csubseteq+%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) in the inner summation appears
in the inner summation appears  times in the outer summation for a given size
times in the outer summation for a given size 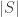 . Using the identity
. Using the identity

 , and looking for patterns. Following is the conjectured optimal strategy which holds for
, and looking for patterns. Following is the conjectured optimal strategy which holds for  :
: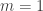 , then as pointed out in the previous post, write down the same answer
, then as pointed out in the previous post, write down the same answer  , write one answer
, write one answer 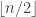 times, and another (different) answer
times, and another (different) answer  times.
times.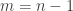 , select an “almost-permutation,” corresponding to the integer partition
, select an “almost-permutation,” corresponding to the integer partition  , so that exactly one answer gets duplicated (and thus exactly one answer is missing).
, so that exactly one answer gets duplicated (and thus exactly one answer is missing). , in which case (b) just select a random permutation. I think (a) is what intuition would suggest is always the optimal approach– it was my wife’s immediate response when I described the problem to her– but I don’t have a good explanation for the qualification (b).
, in which case (b) just select a random permutation. I think (a) is what intuition would suggest is always the optimal approach– it was my wife’s immediate response when I described the problem to her– but I don’t have a good explanation for the qualification (b).