
Consider the following problem: given a value in the MATLAB programming language, can we serialize it into a sequence of bytes– suitable for, say, storage on disk– in a form that allows easy recovery of the exact original value?
Although I will eventually try to provide an actual solution, the primary motivation for this post is simply to point out some quirks and warts of the MATLAB language that make this problem surprisingly difficult to solve.
“Binary” serialization
Our problem requires a bit of clarification, since there are at least a couple of different reasonable use cases. First, if we can work with a stream of arbitrary opaque bytes– for example, if we want to send and receive MATLAB data on a TCP socket connection– then there is actually a very simple and robust built-in solution… as long as we’re comfortable with undocumented functionality. The function b=getByteStreamFromArray(v) converts a value to a uint8 array of bytes, and v=getArrayFromByteStream(b) converts back. This works on pretty much all types of data I can think of to test, even Java- and user-defined class instances.
Text serialization
But what if we would like something human-readable (and thus potentially human-editable)? That is, we would like a function similar to Python’s repr, that converts a value to a char string representation, so that eval(repr(v)) “equals” v. (I say “‘equals'” because even testing such a function is hard to do in MATLAB. I suppose the built-in function isequaln is the closest approximation to what we’re looking for, but it ignores type information, so that isequaln(int8(5), single(5)), for example.)
Without further ado, following is my attempt at such an implementation, to use as you wish:
function s = repr(v)
%REPR Return string representation of value such that eval(repr(v)) == v.
%
% Class instances, NaN payloads, and function handle closures are not
% supported.
if isstruct(v)
s = sprintf('cell2struct(%s, %s)', ...
repr(struct2cell(v)), repr(fieldnames(v)));
elseif isempty(v)
sz = size(v);
if isequal(sz, [0, 0])
if isa(v, 'double')
s = '[]';
elseif ischar(v)
s = '''''';
elseif iscell(v)
s = '{}';
else
s = sprintf('%s([])', class(v));
end
elseif isa(v, 'double')
s = sprintf('zeros(%s)', mat2str(sz, 17));
elseif iscell(v)
s = sprintf('cell(%s)', mat2str(sz, 17));
else
s = sprintf('%s(zeros(%s))', class(v), mat2str(sz, 17));
end
elseif ~ismatrix(v)
nd = ndims(v);
s = sprintf('cat(%d, %s)', nd, strjoin(cellfun(@repr, ...
squeeze(num2cell(v, 1:(nd - 1))).', ...
'UniformOutput', false), ', '));
elseif isnumeric(v)
if ~isreal(v)
s = sprintf('complex(%s, %s)', repr(real(v)), repr(imag(v)));
elseif isa(v, 'double')
s = strrep(repr_matrix(@arrayfun, ...
@(x) regexprep(char(java.lang.Double.toString(x)), ...
'\.0$', ''), v, '[%s]', '%s'), 'inity', '');
elseif isfloat(v)
s = strrep(repr_matrix(@arrayfun, ...
@(x) regexprep(char(java.lang.Float.toString(x)), ...
'\.0$', ''), v, '[%s]', 'single(%s)'), 'inity', '');
elseif isa(v, 'uint64') || isa(v, 'int64')
t = class(v);
s = repr_matrix(@arrayfun, ...
@(x) sprintf('%s(%s)', t, int2str(x)), v, '[%s]', '%s');
else
s = mat2str(v, 'class');
end
elseif islogical(v) || ischar(v)
s = mat2str(v);
elseif iscell(v)
s = repr_matrix(@cellfun, @repr, v, '%s', '{%s}');
elseif isa(v, 'function_handle')
s = sprintf('str2func(''%s'')', func2str(v));
else
error('Unsupported type.');
end
end
function s = repr_matrix(map, repr_scalar, v, format_matrix, format_class)
s = strjoin(cellfun(@(row) strjoin(row, ', '), ...
num2cell(map(repr_scalar, v, 'UniformOutput', false), 2).', ...
'UniformOutput', false), '; ');
if ~isscalar(v)
s = sprintf(format_matrix, s);
end
s = sprintf(format_class, s);
end
That felt like a lot of work… and that’s only supporting the “plain old data” types: struct and cell arrays, function handles, logical and character arrays, and the various floating-point and integer numeric types. As the help indicates, Java and classdef instances are not supported. A couple of other cases are only imperfectly handled as well, as we’ll see shortly.
Struct arrays
The code starts with struct arrays. The tricky issue here is that struct arrays can not only be “empty” in the usual sense of having zero elements, but also– independently of whether they are empty– they can have no fields. It turns out that the struct constructor, which would work fine for “normal” structures with one or more fields, has limited expressive power when it comes to field-less struct arrays: unless the size is 1×1 or 0x0, some additional concatenation or reshaping is required. Fortunately, cell2struct handles all of these cases directly.
Multi-dimensional arrays
Next, after handling the tedious cases of empty arrays of various types, the ~ismatrix(v) test handles multi-dimensional arrays– that is, arrays with more than 2 dimensions. I could have handled this with reshape instead, but I think this recursive concatenation approach does a better job of preserving the “visual shape” of the data.
In the process of testing this, I learned something interesting about multi-dimensional arrays: they can’t have trailing singleton dimensions! That is, there are 1×1 arrays, and 2×1 arrays, even 1x2x3 and 2x1x3 arrays… but no matter how hard I try, I cannot construct an mxnx1 array, or an mxnxkx1 array, etc. MATLAB seems to always “squeeze” trailing singleton dimensions automagically.
Numbers
The isnumeric(v) section is what makes this problem almost comically complicated. There are 10 different numeric types in MATLAB: double and single precision floating point, and signed and unsigned 8-, 16-, 32-, and 64-bit integers. Serializing arrays of these types should be the job of the built-in function mat2str, which we do lean on here, but only for the shorter integer types, since it fails in several ways for the other numeric types.
First, the nit-picky stuff: I should emphasize that my goal is “round-trip” reproducibility; that is, after converting to string and back, we want the underlying bytes representing the numeric values to be unchanged. Precision is one issue: for some reason, MATLAB’s default seems to be 15 decimal digits, which isn’t enough– by two— to accurately reproduce all double precision values. Granted, this is an optional argument to mat2str, which effectively uses sprintf('%.17g',x) under its hood, but Java’s algorithm does a better job of limiting the number of digits that are actually needed for any given value.
Other reasons to bypass mat2str are that (1) for some reason it explicitly “erases” negative zero, and (2) it still doesn’t quite accurately handle complex numbers involving NaN, although it has improved in recent releases. Witness eval(mat2str(complex(0, nan))), for example. (My implementation isn’t perfect here, either, though; there are multiple representations of NaN, but this function strips any payload.)
But MATLAB’s behavior with 64-bit integer types is the most interesting of all, I think. Imagine things from the parser’s perspective: any numeric literal defaults to double precision, which, without a decimal point or fractional part, we can think of as “almost” an int54. There is no separate syntax for integer literals; construction of “literal” values of the shorter (8-, 16-, and 32-bit) integer types effectively casts from that double-precision literal to the corresponding integer type.
But for uint64 and int64, this doesn’t work… and for a while (until around R2010a), it really didn’t work– there was no way to directly construct a 64-bit integer larger than 2^53, if it wasn’t a power of two!
This behavior has been improved somewhat since then, but at the expense of added complexity in the parser: the expression [u]int64(expr) is now a special case, as long as expr is an integer literal, with no arithmetic, imaginary part, etc. Even so much as a unary plus will cause a fall back to the usual cast-from-double. (It appears that Octave, at least as of version 4.0.3, has not yet worked this out.)
The effect on this serialization function is that we have to wrap that explicit uint64 or int64 construction around each individual integer scalar, instead of a single cast of the entire array expression as we can do with all of the other numeric types.
Function handles
Finally, function handles are also special. First, they must be scalar (i.e., 1×1), most likely due to the language syntax ambiguity between array indexing and function application. But function handles also can have workspace variables associated with them– usually when created anonymously– and although an existing function handle and its associated workspace can be inspected, there does not appear to be a way to create one from scratch in a single evaluatable expression.
 coins from bag
coins from bag  of coins available in each bag (where, for example,
of coins available in each bag (where, for example, 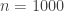 above)? From the IBM Research page:
above)? From the IBM Research page: then one can identify the [subset of] counterfeit bags using a single measurement with an accurate weighing scale. (How?)
then one can identify the [subset of] counterfeit bags using a single measurement with an accurate weighing scale. (How?)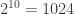 possible subsets of bags may be counterfeit, and our objective is to determine which subset, with just a single weighing of coins carefully chosen from each bag.
possible subsets of bags may be counterfeit, and our objective is to determine which subset, with just a single weighing of coins carefully chosen from each bag. coins in each bag, not 1024; and (b) even this stronger bound is not tight– that is, even before approaching the “real” problem asked in this month’s IBM Research puzzle, the following simpler variant is equally interesting:
coins in each bag, not 1024; and (b) even this stronger bound is not tight– that is, even before approaching the “real” problem asked in this month’s IBM Research puzzle, the following simpler variant is equally interesting: