
Introduction
“No two rainbows are the same. Neither are two packs of Skittles. Enjoy an odd mix.” – Skittles label
Analyzing packs of Skittles (or sometimes M&Ms) seems to be a very common exercise in introductory statistics. How many candies are in each pack? How many candies of each individual color? Are the colors uniformly distributed?
The motivation for this post is to ask some questions raised by the claim in the above quote:
- How many different possible packs of Skittles are there? Here we consider two packs of Skittles to be distinguishable only by the number of candies of each color.
- What is the probability that two randomly purchased packs of Skittles are the same?
- What is the expected number of packs that must be purchased until first encountering a duplicate?
Number of possible packs
If there are 
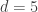

Interestingly, a Skittles commercial from the 1990s suggests that there are 371,292 different possible packs (about 27 seconds into the video). It’s not clear whether this number is based on any mathematics or just marketing… but it’s actually reasonably close to the value 367,290 that we get with the above formula assuming that there are 
However, the total number of candies varies from pack to pack. Most studies suggest an average of about 60 candies per pack– with 635,376 possible packs of exactly that size– and this study includes a couple of outlier packs with as few as 42 and as many as 85 candies. We can sum the binomial coefficients over this range of possible pack sizes, to get 42,578,514 possible distinguishable packs… but fortunately, we can more conservatively allow for all pack sizes from empty up to, say, 100 candies, and still remain within an order of magnitude, and confidently assert that there are at most 100 million different possible packs of Skittles.

Total number of possible packs of Skittles, from “empty” to given maximum number of candies per pack.
Mars Wrigley Confectionery advertises 200 million individual candies produced every day; if we make the extremely conservative assumption that these are distributed among equal numbers of packs of various sizes (i.e., for very 2.17-ounce pack, there is, for example, a corresponding 3.4-pound party pack), so that the 2.17-ounce packs make up only about 1.6% of total production, this works out to approximately 50,000 packs per day. By the pigeonhole principle, after only about 1800 days of production, there must be two identical packs of Skittles out there somewhere… but identical packs are likely much more common than this worst-case analysis suggests, as we’ll see shortly.
Probability of identical packs
The second question requires a bit more work. Let’s temporarily assume that there are always exactly 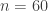

Instead, let’s assume that each individual candy’s color is independently and identically distributed, with each of the
This tracks very well with the actual observed distribution of colors of candies within and across packs. Some packs have more yellows, some have more reds, etc., but there is almost never a color missing, and almost never exactly the same number of every color… but with more and more observed packs, the overall distribution of colors is indeed very nearly uniform. In other words, although it can be unintuitive, giving the impression of “designed” non-uniformity of the distribution of colors, we should expect variability using this uniform model, even for a seemingly “large” sample from, say, a party-size bag of over a thousand candies.
So, given two randomly purchased packs each with 

^2)^d](https://s0.wp.com/latex.php?latex=p%28n%2Cd%29+%3D+%5Cfrac%7B1%7D%7Bd%5E%7B2n%7D%7D%5B%5Cfrac%7Bx%5E%7B2n%7D%7D%7B%28n%21%29%5E2%7D%5D%28%5Csum%5Climits_%7Bk%3D0%7D%5En+%28%5Cfrac%7Bx%5Ek%7D%7Bk%21%7D%29%5E2%29%5Ed+&bg=ffffff&fg=333333&s=2&c=20201002)
For completeness, following is example C++ source code for computing these probabilities using arbitrary-precision rational arithmetic:
#include "math_Rational.h"
#include
<map>
#include <iostream>
using namespace math;
// Map powers of x to coefficients.
typedef std::map<int, Rational> Poly;
// Return f(x)*g(x) mod x^m.
Poly product_mod(Poly f, Poly g, int m)
{
Poly h;
for (int k = 0; k < m; ++k)
{
for (int j = 0; j <= k; ++j)
{
h[k] += f[j] * g[k - j];
}
}
return h;
}
Rational p(int n, int d)
{
// Compute g(x) = 1 + ... + (x^n/n!)^2.
Poly g; g[0] = 1;
Rational factorial = 1, d_2n = 1;
for (int k = 1; k <= n; ++k)
{
factorial *= k;
d_2n *= (d * d);
g[2 * k] = 1 / (factorial * factorial);
}
// Compute f(x) = g(x)^d mod x^(2n+1).
Poly f; f[0] = 1;
for (int k = 0; k < d; ++k)
{
f = product_mod(f, g, 2 * n + 1);
}
// Return [x^(2n)]f(x) * (n!)^2 / d^(2n).
return f[2 * n] * (factorial * factorial) / d_2n;
}
int main()
{
std::cout << p(60, 5) << std::endl;
}
This yields, for example, 
(Aside: This is effectively the same problem as discussed here a couple of years ago.)
However, we must again account for the variability in total number 


Fortunately, the variance of the approximately normally distributed pack size (we can be reasonably confident in the mean of 60) doesn’t change the answer much: the probability that two randomly purchased packs– of possibly different sizes– will be identical is somewhere between about 1/100,000 and 1/200,000.
Expected number of packs until first duplicate
Finally, question (3) is essentially a messy birthday problem: instead of insisting that a particular pair of Skittles packs be identical, how many packs must we buy on average for some pair to be identical? The numbers from question (2) in the hundred thousands may seem large, but a back-of-the-envelope square-root estimate of “only” about 400-500 packs to find a duplicate was, to me, surprisingly small. This is confirmed by simulation: let’s assume that every pack of Skittles independently contains a (100,0.6)-binomially distributed number of candies– for a mean of 60 candies per pack– with each individual candy’s color independently uniformly distributed. We repeatedly buy packs until we first encounter one that is identical to one we have previously purchased. The figure below shows the distribution of the number of packs we need to buy, based on one million Monte Carlo simulations, where the mean of 524 packs is shown in red.

Distribution of number of packs needed until encountering a first duplicate.
A box of 36 packs of Skittles costs about 21 dollars… so an experiment to search for two identical packs should only cost about $300… on average.
[Edit: See this follow-up post describing the results of this experiment.]
