
Introduction
We often need “random” numbers to simulate effects that are practically non-deterministic, such as measurement noise, reaction times of human operators, etc. However, we also need to be able to reproduce experimental results– for example, if we run hundreds of Monte Carlo iterations of a simulation, and something weird happens in iteration #137, whether a bug or an interesting new behavior, we need to be able to go back and reproduce that specific weirdness, exactly and repeatably.
Pseudo-random number generators are designed to meet these two seemingly conflicting requirements: generate one or more sequences of numbers having the statistically representative appearance of randomness, but with a mechanism for exactly reproducing any particular such sequence repeatably.
The motivation for this post is to describe the behavior of pseudo-random number generation in several common modeling and simulation environments: Python, MATLAB, and C++. In particular, given a sequence of random numbers generated in one of these environments, how difficult is it to reproduce that same sequence in another environment?
Mersenne Twister
In many programming languages, including Python, MATLAB, and C++, the default, available-out-of-the-box random number generator is the Mersenne Twister. Unfortunately, despite its ubiquity, this generator is not always implemented in exactly the same way, which can make reproducing simulated randomness across languages tricky. Let’s look at each of these three languages in turn.
(As an aside, it’s worth noting that the Mersenne Twister has an interesting reputation. Although it’s certainly not optimal, it’s also not fundamentally broken, but lately it seems to be fashionable to sniff at it like it is, in favor of more recently developed alternatives. Those alternatives are sometimes justified by qualitative arguments or even quantitative metrics that are, in my opinion, often of little practical consequence in many actual applications. But that is another much longer post.)
Python
Python is arguably the easiest environment in which to reproduce the behavior of the original reference C implementation of the Mersenne Twister. Python’s built-in random.random(), as well as Numpy’s legacy numpy.random.random(), both use the same reference genrand_res53 method for generating a double-precision random number uniformly distributed in the interval [0,1):
- Draw two 32-bit unsigned integer words
.
- Concatenate the high 27 bits of
with the high 26 bits of
.
- Divide the resulting 53-bit integer by
, yielding a value in the range
.
So given the same generator state, both the built-in and Numpy implementations yield the same sequence of double-precision values as the reference implementation.
Seeding is slightly messier, though. The reference C implementation provides two methods for seeding: init_genrand takes a single 32-bit word as a seed, while init_by_array takes an array of words of arbitrary length. Numpy’s numpy.random.seed(s) behaves like init_genrand when the provided seed is a single 32-bit word. However, the built-in random.seed(s) always uses the more general init_by_array, even when the provided seed is just a single word… which yields a different generator state than the corresponding call to init_genrand.
MATLAB
Although MATLAB provides several different generators, the Mersenne Twister has been the default since 2005. Its seeding method rng(s) is “almost” exactly like the reference init_genrand(s)— and thus like numpy.random.seed(s)— accepting a single 32-bit word as a seed… except that s=0 is special, being shorthand for the “default” seed value s=5489.
The rand() function is also “almost” identical to the reference genrand_res53 described above… except that it returns random values in the open interval (0,1) instead of the half-open interval [0,1). There is an explicit rejection-and-resample if zero is generated. It’s an interesting question whether this has ever been observed in the wild: it’s confirmed not to occur anywhere in the first 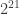
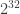
C++
Both Visual Studio and GCC implementations of the Mersenne Twister in std::mt19937 (which is also the std::default_random_engine in both cases) allow for the same single-word seeding as the reference init_genrand (and numpy.random.seed, and MATLAB’s rng excepting the special zero seed behavior mentioned above).
However, the C++ approach to generating random values from std::uniform_real_distribution<double> is different from the reference implementation used by Python and MATLAB:
- Draw two 32-bit unsigned integer words
- Concatenate all 32 bits of
- Divide the resulting 64-bit integer by
.
By using all 64 bits, this has the effect of allowing generation of more than just
Another important difference here from the reference implementation is that the two random words are reversed: the first 32-bit word forms the least significant 32 bits of the fraction, and the second word forms the most significant bits. I am not sure if there is any theoretically justified reason for this difference. One possible practical justification, though, might be to prevent confusion when comparing with the reference implementation: even for the same seed, these random double-precision values “look” nothing at all like those from the reference implementation. Without the reversal, this sequence would be within the eyeball norm of the reference, matching in the most significant 27 or more bits, but not yielding exactly the same sequence.
