The wager described in the previous post was motivated by an interesting recent paper (Miller and Sanjurjo, reference below) discussing the hot hand, or the perception in some sports, particularly basketball, that a player with a streak of successful shots (“He’s heating up!”) has an increased probability of making a subsequent shot and continuing the streak (“He’s on fire!”).
Whether being on a streak yourself, or trying to defend a player on a streak, on the court this certainly feels like a real phenomenon. But is the hot hand a real effect, or just another example of our human tendency to see patterns in randomness?
A famous 1985 paper (Gilovich, Vallone, and Tversky, reference below) argued the latter, analyzing the proportion of successful shots immediately following a streak of three made shots in various settings (NBA field goals, free throws, and a controlled experiment with college players). Not finding any significant increase in proportion of “streak-extending” shots made, the apparent conclusion would be that a past streak has no effect on current success.
But that’s where this puzzle comes in: even if basketball shots are truly iid with success probability  , we should expect a negative bias in the proportion of shots made following a streak, at least compared to the intuitively expected proportion . Miller and Sanjurjo argue that the absence of this bias in the 1985 data suggests that the hot hand is not just “a cognitive illusion.”
, we should expect a negative bias in the proportion of shots made following a streak, at least compared to the intuitively expected proportion . Miller and Sanjurjo argue that the absence of this bias in the 1985 data suggests that the hot hand is not just “a cognitive illusion.”
Both papers are interesting reads. In presenting the problem here as a gambling wager, I simplified things somewhat down to a “win, lose, or push” outcome (i.e., were there more streak-extending successes than failures, or fewer), since the resulting exact expected return can be computed more efficiently than the expected proportion of successes following a streak:
Given  remaining trials (basketball shots, coin flips, whatever) with success probability , noting outcomes following streaks of length
remaining trials (basketball shots, coin flips, whatever) with success probability , noting outcomes following streaks of length  , and winning (losing) the overall wager if the number of streak-extending successes is greater (less) than the number of streak-ending failures, the expected return is
, and winning (losing) the overall wager if the number of streak-extending successes is greater (less) than the number of streak-ending failures, the expected return is  , computed recursively via
, computed recursively via



where, using the setup in the previous post where we flip  fair coins with probability
fair coins with probability 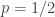 of heads, looking for heads extending streaks of length
of heads, looking for heads extending streaks of length  , the expected return
, the expected return  is about -0.150825.
is about -0.150825.
References:
- Gilovich, T., Vallone, R., and Tversky, A., The Hot Hand in Basketball: On the Misperception of Random Sequences, Cognitive Psychology, 17(3) July 1985, p. 295-314 [PDF]
- Miller, Joshua B. and Sanjurjo, Adam, Surprised by the Hot Hand Fallacy? A Truth in the Law of Small Numbers, Econometrica, 86(6) November 2018, p. 2019-2047 [arXiv]




![E[U] = \frac{1}{{2n \choose n}} \cdot 2\sum\limits_{u=1}^n \sum\limits_{k=1}^{\lfloor n/u \rfloor} (-1)^{k-1}{2n \choose n-ku}](https://s0.wp.com/latex.php?latex=E%5BU%5D+%3D+%5Cfrac%7B1%7D%7B%7B2n+%5Cchoose+n%7D%7D+%5Ccdot+2%5Csum%5Climits_%7Bu%3D1%7D%5En+%5Csum%5Climits_%7Bk%3D1%7D%5E%7B%5Clfloor+n%2Fu+%5Crfloor%7D+%28-1%29%5E%7Bk-1%7D%7B2n+%5Cchoose+n-ku%7D+&bg=ffffff&fg=333333&s=2&c=20201002)
![E[U]](https://s0.wp.com/latex.php?latex=E%5BU%5D&bg=ffffff&fg=333333&s=0&c=20201002)




