Introduction
“This shouldn’t take long,” Alice says. “It’s only flipping a coin, after all.”
Alice and Bob are talking in the hallway at work. Alice has been tasked with analyzing the behavior of a simple black box. When a button on the side of the box is pressed, a mechanism inside the box flips a biased coin, and displays either a green light when the coin comes up heads– with some fixed but unknown probability  — or a red light when it comes up tails.
— or a red light when it comes up tails.
“As we discussed in the meeting, I will press the button to flip the coin 200 times, observe the number of green and red light indications, and report the resulting 95% confidence interval bounds for — to two digits, as usual*.”
“That’s great for you,” Bob grumbles. “I’m the one stuck with analyzing the Rube Goldberg Variation.”
Bob’s task is more involved. The Rube Goldberg Variation is a much larger black box, taking up almost an entire room. Instead of just a button on the outside of the box, there is a dial as well, that may be set to a positive integer  specifying the “mode” in which the box is configured.
specifying the “mode” in which the box is configured.
The mechanism inside is much more complex as well: pressing the button on the side of the box starts a convoluted sequence of interacting mechanisms inside, many of which exhibit some randomness similar to Alice’s coin flip. This process takes several minutes… but eventually, the box displays either a green light indicating “success” — with some fixed but unknown probability 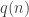 that depends on the selected mode– or a red light indicating “failure.”
that depends on the selected mode– or a red light indicating “failure.”
“I suppose the good news is that at least we’re only focusing on the one mode 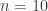 ,” Bob says. “But this analysis is still going to take days to complete. Not only does each single experiment– from pressing the button to observing the light– take longer, but I will also need more sample outcomes of the experiment to estimate
,” Bob says. “But this analysis is still going to take days to complete. Not only does each single experiment– from pressing the button to observing the light– take longer, but I will also need more sample outcomes of the experiment to estimate 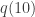 with the same degree of certainty.”
with the same degree of certainty.”
Alice looks confused. “Wait, why do you need more samples? Shouldn’t the usual 200 be enough?”
Bob replies, “If it were just a coin flip, sure. But the Rube Goldberg Variation has a lot more moving parts, with a lot more opportunities to introduce randomness into the process. I need more samples to cover all of the possible combinations of corner-case interactions between all of those components.”
Monte Carlo simulation
This post is motivated by Bob. Recently, Bob was an undergraduate student… but I’ve also encountered discussions like the one above when Bob has been a computer scientist with a Ph.D. So, this is my attempt to capture my thoughts on this subject, to hopefully highlight the specific areas where there are potential pitfalls and opportunities for confusion.
In these past discussions, there were not any actual black boxes. Instead, there were computer simulations of the processes inside hypothetical black boxes. For example, the simulation of Alice’s black box might look like this (in Python):
def alice():
return 1 if random.random() < 0.75 else 0
where we can estimate the probability of success by evaluating alice() many times and averaging the results. Of course, that would be a bit ridiculous if we were allowed to inspect the source code, since we could just read directly that  .
.
But now consider Bob’s more complicated simulation:
def bob(n):
position = 1
while True:
while True:
move = random.randint(-1, 1)
if 1 <= position + move <= n:
break
position = position + move
if move == 0:
break
return 1 if position == 1 else 0
(In reality, Bob’s simulation should be much more complicated than this, with so many lines of code, and so many random components, that analysis by inspection is practically impossible. But I can’t resist inserting a tractable puzzle even when it’s not the point: inside this black box, there are slots arranged in a row, with a marble initially in the left-most slot. When Bob presses the button, the marble makes a series of random moves, with each move selected uniformly from {left, stop, right}. An attempt to move left beyond the left-most slot, or right beyond the right-most slot, is ignored. The marble moves randomly back and forth along the row of slots, until a “stop” move, resulting in display of a “successful” green light if the marble stops in its original left-most slot, or a “failure” red light otherwise.)
It’s at least not as immediately clear from inspection alone what is the probability that bob(n) returns 1… indeed, with those nested while True loops in there, it might not be obvious whether this function is guaranteed to return at all (fortunately, it is– more on this later).
So, to level the playing field, so to speak, let’s suppose that neither Alice nor Bob is able to inspect their simulation source code at all. In other words, neither is allowed to open their black box and peek inside; all either can do is inspect their black box’s output, observed from repeatedly pressing the button on the side of the box. (Remember, Bob was the one complaining; so we’re trying to remove any unfair advantage that Alice might have.)
Given this setup, we are considering the following question: because Bob’s simulation is more complex, does he require more sample executions of his simulation to estimate , than Alice requires to estimate with the same degree of certainty?
A simulation is a function
I think it’s helpful to think of a simulation like those above as a function, in the mathematical sense; that is, a simulation is a function

that maps its input to a binary output 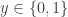 , that is,
, that is,
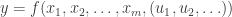
where the output 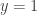 means “success” and
means “success” and 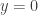 means “failure.”
means “failure.”
The input parameters  specify the configurable “mode” of the simulation. In Alice’s case,
specify the configurable “mode” of the simulation. In Alice’s case, 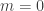 since her simulation isn’t configurable. In Bob’s case,
since her simulation isn’t configurable. In Bob’s case, 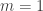 and
and  , where he is interested in the specific case
, where he is interested in the specific case  .
.
The inputs 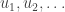 specify a single realized sample of a pseudo-random number stream, where each
specify a single realized sample of a pseudo-random number stream, where each 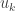 is drawn independently and uniformly from the unit half-open interval
is drawn independently and uniformly from the unit half-open interval  . This is enough expressive power to represent effects of the random processes in any computable simulation: in the context of the Python implementations above, each is the result of the k-th evaluation of
. This is enough expressive power to represent effects of the random processes in any computable simulation: in the context of the Python implementations above, each is the result of the k-th evaluation of random.random(), which we can think of as the “subroutine” in terms of which all other pseudo-random functions, like random.randint(a, b), or random.gauss(mu, sigma), etc., may be implemented.
(Pseudo) randomness
I think viewing the “random” behavior of a computer simulation in this mathematical way is useful, since it forces us to consider some important implementation details. Note that by specifying our simulation as a function, we require that the function be well-defined. That is, every possible input must map to a unique output.
Input must map to a unique output: in other words, our simulation must be repeatable. Given the same input values– specifying both the configuration parameters as well as the sampled random number stream — the simulation must always return the same output value, either always 0 or always 1. Output cannot vary depending on “hidden” additional factors outside the domain of the function, such as the system clock’s indication of the current time, etc.
Every input must map to an output: here we need to be careful about guaranteeing that our simulation will terminate. That is, in any particular practical execution of the simulations above, we never need the entire sequence of “available” random numbers (since otherwise it would run forever). For example, Alice’s simulation only ever depends on the first random draw  . Bob’s simulation, on the other hand, depends on an unbounded but finite number of draws that varies from one run to the next. That is, there is a positive probability that running the simulation could take an hour, or a week, or a year, or any specified amount of time, no matter how long… but there is zero probability that it will run forever.
. Bob’s simulation, on the other hand, depends on an unbounded but finite number of draws that varies from one run to the next. That is, there is a positive probability that running the simulation could take an hour, or a week, or a year, or any specified amount of time, no matter how long… but there is zero probability that it will run forever.
But there are input sequences in the domain of the simulation function that correspond to this “run forever” behavior. For example, in Bob’s simulation, what if the marble selects the “left” move at every turn? Or alternates “left” and “right,” without ever selecting “stop”? For our function to be well-defined, we still need to assign some output to any and all of these infinite-length inputs in the domain, even if they have zero probability of occurring.
The good news is that we can assign any output we want… because it doesn’t matter! That is, no matter what questions we might ask about the statistical behavior of the output of a (terminating) simulation, the answers do not depend on our choice of assignment of outputs to those “impossible” outcomes.
More precisely, we can change our perspective slightly, and view our simulation function as a random variable  on the sample space
on the sample space  with its natural probability measure, parameterized by the simulation mode:
with its natural probability measure, parameterized by the simulation mode:

where we don’t care about the output from those “impossible” outcomes because they have measure zero. Note that this is essentially just a notational change, not a conceptual one: a random variable is neither random, nor a variable; it’s simply a function, just like we started with. This random variable has a Bernoulli distribution, whose parameter 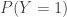 we are trying to estimate… which we can do, no matter the “complexity” of the simulation realizing the function .
we are trying to estimate… which we can do, no matter the “complexity” of the simulation realizing the function .
Conclusion
So, the answer to the question posed here– does Bob need more random samples than Alice to do his job– is no. The black boxes are black; we can’t peek inside them. They are effectively indistinguishable by anything other than their behavior. Similarly, a function implementing a simulation is characterized not by its “complexity” of “implementation,” but solely by its mapping of inputs to outputs.
I’m pretty sure I’ve already beaten this horse to death. But there are several other interesting wrinkles not discussed here. For example, we often want to actually no-kidding repeat exactly the same past simulation behavior (when debugging, for example); this capability is managed by using and recording seeds and/or substream indices as “shorthand” for the infinite sequences of input random numbers. Also, the input configuration parameters have so far been mostly just additional notational noise. But that configurability can lead to additional analysis pitfalls, when combining Monte Carlo observations of simulation runs across different values of those configuration parameters.
Notes
(*) When reporting on results of the analysis, why the frequentist Clopper-Pearson confidence interval instead of a more fashionable Bayesian approach of reporting, say, the (narrowest) highest density credible interval with, say, a uniform prior? Since those decisions weren’t really the point here, I chose the experimental setup carefully, so that it doesn’t matter: the resulting intervals, reported to two digits of precision, will be the same either way. If there is any safe place to be a frequentist, it’s on a computing cluster.

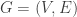 , with a vertex for each person, and an edge between a pair of vertices representing the (symmetric) friendship relation.
, with a vertex for each person, and an edge between a pair of vertices representing the (symmetric) friendship relation. in the graph
in the graph  . How many friends does Victor have? This “friend count” is
. How many friends does Victor have? This “friend count” is
 and
and  are the
are the 
 to be the “surplus friend count,” that is, the difference between Victor’s friend count and his friends’ average friend count:
to be the “surplus friend count,” that is, the difference between Victor’s friend count and his friends’ average friend count:
![\mathbf{E}\left[X(v)\right] \leq 0](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5Cleft%5BX%28v%29%5Cright%5D+%5Cleq+0&bg=ffffff&fg=333333&s=0&c=20201002) , with equality only when every component of
, with equality only when every component of  for each edge
for each edge  .)
.) . But all that we have shown is that
. But all that we have shown is that ![\mathbf{E}\left[X(v)\right] < 0](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5Cleft%5BX%28v%29%5Cright%5D+%3C+0&bg=ffffff&fg=333333&s=0&c=20201002) (assuming variable friend counts), which at best implies, via the pigeonhole principle, that there exists at least one person whose friends have more friends than they do.
(assuming variable friend counts), which at best implies, via the pigeonhole principle, that there exists at least one person whose friends have more friends than they do.
 , or 1 in 9.2 quintillion exact probability of guessing any year’s outcome correctly, if you simply flip a fair coin to determine the winner of each game. The constant blue and red lines at the top indicate the estimated probability of a “chalk” bracket outcome, always picking the higher seeded team to win each match-up. (The blue and red colors reflect two different models of game probabilities as a function of difference in “strength” of each team; as discussed in the linked article, blue indicates a strength following a normal distribution density, and red indicates a simpler linear strength function.)
, or 1 in 9.2 quintillion exact probability of guessing any year’s outcome correctly, if you simply flip a fair coin to determine the winner of each game. The constant blue and red lines at the top indicate the estimated probability of a “chalk” bracket outcome, always picking the higher seeded team to win each match-up. (The blue and red colors reflect two different models of game probabilities as a function of difference in “strength” of each team; as discussed in the linked article, blue indicates a strength following a normal distribution density, and red indicates a simpler linear strength function.)
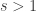 times in this list of exact cover solutions, once for each way of positioning and orienting all of its particular polycubes. For example, even those puzzles with a unique solution will appear
times in this list of exact cover solutions, once for each way of positioning and orienting all of its particular polycubes. For example, even those puzzles with a unique solution will appear 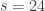 times, once for each possible rotation of the solved cube. The Soma cube appears
times, once for each possible rotation of the solved cube. The Soma cube appears  times, with 24 “copies” of the 480 solutions that we would typically consider truly distinct, differing by more than just a rotation of the solved cube.
times, with 24 “copies” of the 480 solutions that we would typically consider truly distinct, differing by more than just a rotation of the solved cube. — the larger the number of oriented solutions– for a given puzzle, the “easier” it should be to solve. For example, the figure below shows one of the two puzzles maximizing
— the larger the number of oriented solutions– for a given puzzle, the “easier” it should be to solve. For example, the figure below shows one of the two puzzles maximizing 
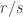 , where the numerator
, where the numerator  is the “breadth” of the brute force search tree. More precisely,
is the “breadth” of the brute force search tree. More precisely, 


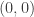 when the basket is full, to
when the basket is full, to 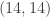 when the basket is empty, with a north step corresponding to drawing an unmatched sock and placing it on the chair, and an east step corresponding to drawing a sock whose counterpart is already on the chair, removing, folding, and placing the pair in the drawer.
when the basket is empty, with a north step corresponding to drawing an unmatched sock and placing it on the chair, and an east step corresponding to drawing a sock whose counterpart is already on the chair, removing, folding, and placing the pair in the drawer. . (That is, we can’t have a negative number of socks on the chair.) There are
. (That is, we can’t have a negative number of socks on the chair.) There are  of these paths (more on this later); of these, the number of successful drawing sequences, never running out of room on the chair, by also never touching the diagonal
of these paths (more on this later); of these, the number of successful drawing sequences, never running out of room on the chair, by also never touching the diagonal  , is
, is
 . (That is, multiple socks on the chair must be all left or all right.) This does work, since each equally likely drawing sequence corresponds to a distinct lattice path. (The Riddler column does note that modeling the original problem using lattice paths is “tricky, since the probabilities of transitioning from one state to the next depended on how many paired and unpaired socks remained in the basket.” This is true… but that’s not really why the lattice path calculation doesn’t work in that case– even in this modified problem, state transition probabilities also depend on the composition of socks remaining in the basket.)
. (That is, multiple socks on the chair must be all left or all right.) This does work, since each equally likely drawing sequence corresponds to a distinct lattice path. (The Riddler column does note that modeling the original problem using lattice paths is “tricky, since the probabilities of transitioning from one state to the next depended on how many paired and unpaired socks remained in the basket.” This is true… but that’s not really why the lattice path calculation doesn’t work in that case– even in this modified problem, state transition probabilities also depend on the composition of socks remaining in the basket.) , the number of north-east lattice paths from
, the number of north-east lattice paths from  that do not intersect the diagonals
that do not intersect the diagonals  nor
nor 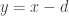 is
is
 , reflect the remainder of this path about that diagonal, so that the endpoint
, reflect the remainder of this path about that diagonal, so that the endpoint  . This establishes a bijection between the complementary set of diagonal-intersecting paths to
. This establishes a bijection between the complementary set of diagonal-intersecting paths to  of initial diagonal intersections yields
of initial diagonal intersections yields
 card from a standard 52-card deck. One additional trump card is dealt face-up indicating the trump suit. Each player in turn starting left of the dealer plays the card from their hand, and the “trick” is won by either the highest-ranked card (ace is high) in the trump suit, or if no trump is played, by the highest-ranked card in the led suit. (In other rounds where
card from a standard 52-card deck. One additional trump card is dealt face-up indicating the trump suit. Each player in turn starting left of the dealer plays the card from their hand, and the “trick” is won by either the highest-ranked card (ace is high) in the trump suit, or if no trump is played, by the highest-ranked card in the led suit. (In other rounds where  , the player that wins the trick leads the next hand, continuing for a total of
, the player that wins the trick leads the next hand, continuing for a total of  tricks in the round; players must follow the led suit if able.)
tricks in the round; players must follow the led suit if able.)
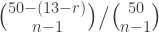

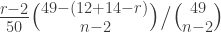


 markings fixed.
markings fixed. markings fixed.
markings fixed. markings fixed.
markings fixed.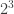 markings fixed.
markings fixed.


 of four horses, we compute the probability of exactly that subset being scratched by solving for
of four horses, we compute the probability of exactly that subset being scratched by solving for  in the linear system of equations in
in the linear system of equations in  variables, indexed by subsets of
variables, indexed by subsets of 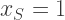
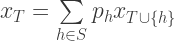
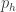 is the single-roll probability of advancing horse
is the single-roll probability of advancing horse 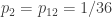 , etc.). In Python with
, etc.). In Python with ![\sum [x^m/m!]G_j(x)](https://s0.wp.com/latex.php?latex=%5Csum+%5Bx%5Em%2Fm%21%5DG_j%28x%29&bg=ffffff&fg=333333&s=0&c=20201002) for horse
for horse 
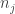 is the number of steps required for horse
is the number of steps required for horse 
 norm (proportional to
norm (proportional to 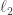 norm, and the
norm, and the 
