This article was discussed on Hacker News.
Introduction
This was a fun nostalgia trip. But it ended up being an attempt to collect and preserve some retro computing history as well… and I also learned– or forgot and remembered?– another interesting quirk of that programming environment from nearly 45 years ago.
In 1981, I had a friend down the street who had an Apple II+. Later that year, my parents hired a tutor for programming lessons. I feel like I owe much of the subsequent course of my life to that time with “Mrs. Cathy,” who had several computers in her home: I remember an Apple II+, a VIC-20, and an IBM PC.
But it wasn’t until 1983 that we got our own home computer, an Apple //e. One of the programs that came with the computer, Lemonade Stand, is shown in the screenshot below.
The game is pretty simple: each morning, based on the weather forecast for the day, you decide how many glasses of lemonade and how many advertising signs to make, and how much to charge for each glass. These decisions and the day’s weather affect demand, you sell some number of glasses, rinse and repeat.
It’s about as fun as it sounds… but I remember being intrigued by the prospect of “reverse engineering” the game. The Applesoft BASIC source code contains the formula for computing the demand and the resulting profit as a function of the player’s inputs and the weather. We can, in principle, “solve” for the inputs that would maximize the expected profit. This post is motivated by my failed attempt to do this.
History
All of the code discussed here, both old and new, is available on GitHub. Let’s start with the old code: lemonade.bas is the Applesoft BASIC source by Charlie Kellner, from the .dsk image of my original 5.25″ diskette. I believe this is the earliest Apple version of the game– for completeness I’ve also included source extracts of two subsequent released versions (lemonade_v4.bas and lemonade_v5.bas), but for our purpose here their behavior is identical, with cosmetic updates to the graphics and sound by Drew Lynch, Bruce Tognazzini, and Jim Gerber.
For comparison, I’ve also extracted the source for selll.bas (as in “sell lemonade”), from the Minnesota Educational Computing Consortium (MECC, of Oregon Trail fame) Elementary Volume 3 disk A704. Although appearing later in 1980, I think this version is somewhat closer to the actual original version of the game written by Bob Jamison in 1973 for the UNIVAC mainframe. That original 1973 source seems to be lost to the mists of antiquity… but I think selll.bas retains more of its parentage than the Kellner version, which removed some helpful comments explaining the terms in the demand function, mistranslated some variable names and GOTO line numbering resulting in unreachable code, etc.
Maximizing profit
Now for the new code: lemonade_strategy.py implements the profit-maximization described above. It’s pure brute force: given the objective function below,
def expected_profit(glasses, signs, price, cost, r1=1, p_storm=0):
n1 = 54 - 2.4 * price if price < 10 else 3000 / (price * price)
demand = min(int(r1 * n1 * (2 - math.exp(-0.5 * signs))), glasses)
revenue = demand * price
expense = glasses * cost + signs * 15
return ((1 - p_storm) * revenue - expense, revenue - expense,
glasses, signs, price)
where r1 and p_storm are functions of the weather forecast, we simply evaluate the expected profit for all feasible inputs and find the maximum, with the wrinkle that the feasible region– how many glasses and signs we can possibly make– also depends on our current assets:
max(expected_profit(glasses, signs, price, cost, r1, p_storm)
for glasses in range(min(1000, assets // cost) + 1)
for signs in range(min(50, (assets - cost * glasses) // 15) + 1)
for price in range(101))
I ended up in this rabbit hole in the usual way, after discussion with a student. My objective wasn’t really to “solve” this decades-old game, but just to give an explicit example of how much slower computers were then: this same brute-force approach in Applesoft BASIC, with the Apple //e’s 1 MHz processor, took nearly 4 hours to compute optimal strategy just for the first sunny day in Lemonsville. That’s over 200,000 times slower than the above Python code, which runs in a fraction of a second on my decade-old 2.6 GHz laptop– that is, with a clock speed “only” 2,600 times faster.
Changing the weather
You can play an Apple version of the game in a browser at the Internet Archive, linked from the game’s Wikipedia page. I did just that, with my Python script running alongside to compute optimal strategy… and it didn’t work.
The first day’s weather was “hot and dry.” With $2.00 and each glass of lemonade costing 2 cents, the optimal strategy should have been to make 74 glasses, 3 advertising signs, and charge 12 cents per glass, for an expected profit of $6.95. But when I entered these values in the game, I only sold 37 glasses, for a lousy $2.51 profit.
What was going on? It turns out that there are many different copies of Lemonade Stand out there, both at the Internet Archive as well as in various Apple II disk image archives… but the particular one linked from Wikipedia is unique among all of these in that it contains an important modification to the source code appearing in none of the other copies, highlighted below:
400 REM WEATHER REPORT
410 SC = RND (1)
420 IF SC < .4 THEN SC = 2: GOTO 460
430 IF SC < .7 THEN SC = 10: GOTO 460
440 SC = 7
460 REM IF D<3 THEN SC=2
(You can play the original unmodified version at the Internet Archive here.)
I don’t know where these changes came from. And I believe these are indeed changes from the original release (i.e., not the other way around). But just these three edits were enough to keep my optimal strategy calculation from producing the correct result. This was strange at first glance, since the above section of code merely computes the randomly generated weather forecast for the day, which is an input to the subsequent profit calculation. In the above modified version, the weather forecast is sunny (SC=2) 40% of the time, cloudy (SC=10) 30% of the time, and hot and dry (SC=7) 30% of the time. The original threshold values are 0.6 and 0.8, corresponding to probabilities (0.6, 0.2, 0.2) of (sunny, cloudy, hot and dry).
The REM in line 460 is a “remark” comment, effectively disabling the original behavior of forcing sunny forecasts for the first two days (when D=1 and D=2) of the game. But again, why should this matter? This is all input to the profit calculation, which remains identical to the original, so what is causing the difference in behavior?
Undeclared variables
To make it easier to poke (!) around this problem, I wrote lemonade.py, which is my attempt at a shot-for-shot remake of the original lemonade.bas in Python, minus the graphics and sound– that is, just a canonical mode text interface, but an otherwise line-for-line direct translation with identical behavior.
That translation process was an interesting exercise, almost a logic puzzle, converting the unstructured GOTO-based flow control of Applesoft BASIC into structured Python– I was surprised at the end of it all to find that only a single defined function and extra temporary Boolean variable were needed, despite all of the GOSUBs.
That translation helped me to understand the cause of the different behavior I was seeing in the original. The problem is in the following section of code, with the offending lines highlighted:
700 REM AFTER 2 DAYS THINGS CAN HAPPEN
710 IF D > 2 THEN 2000
...
2000 REM RANDOM EVENTS
2010 IF SC = 10 THEN 2110
2030 IF SC = 7 THEN 2410
...
2410 X4 = 1
2430 PRINT "A HEAT WAVE IS PREDICTED FOR TODAY!"
2440 R1 = 2
2450 GOTO 805
The variable R1 is an input to the profit function. But although the code change in line 460 above allows the first day’s displayed forecast to be hot and dry– or anything else other than sunny– line 710 still prevents actually setting R1 to reflect that non-sunny forecast when computing profit.
The effect is that, for the first two days, the weather forecast might indicate “hot and dry,” or “cloudy,” etc., but it’s really still sunny for those first two days, just like the original version.
All of which leads to the actual motivation for this post: when I initially tried to reproduce the effect of the three changed lines in the Python version, I got a “NameError: name 'D' is not defined“, due to commenting out line 460 in the BASIC version above: the variable D is never declared or assigned a value prior to line 460.
Python can’t handle this… but apparently Applesoft BASIC can. Variables do not need to be declared before use: when evaluating an expression containing a variable not previously assigned, the value of that variable defaults to zero (or the empty string for string variables).
This behavior is actually depended on in a few other places in the game as well. I admit that I think this is new to me– in all of those early days of learning programming, I don’t remember ever being aware of nor taking advantage of this “feature.” And it’s not a feature of the original Dartmouth BASIC. And I couldn’t find documentation of it anywhere in the books, manuals, and magazines that I have… but I did find it written down in the original “Blue Book” Applesoft Reference Manual. From page 9: “Another important fact is that if a variable is encountered in a formula before it is assigned a value, it is automatically assigned the value zero. Zero is then substituted as the value of the variable in the particular formula.“





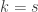

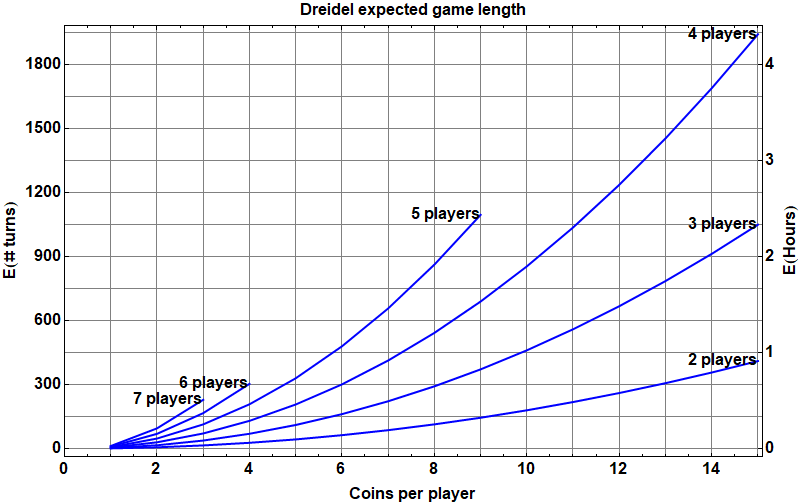
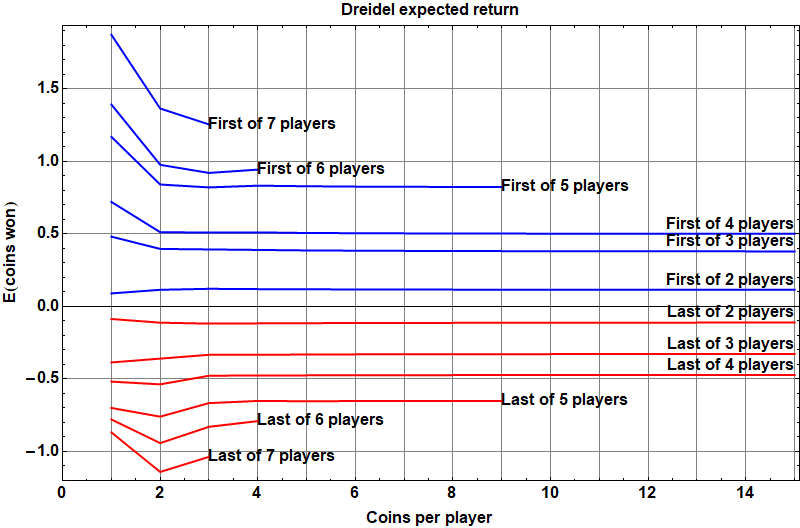
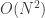 spins, Advances in Applied Mathematics, 36(1) January 2006, p. 85-94 [
spins, Advances in Applied Mathematics, 36(1) January 2006, p. 85-94 [ for each possible game state
for each possible game state  , where
, where  is a
is a 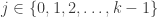 is an integer indicating which player is to roll for the next turn.
is an integer indicating which player is to roll for the next turn.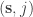 . That’s a lot of variables:
. That’s a lot of variables:  variables, which for
variables, which for 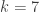 players is already over 8 million variables.
players is already over 8 million variables.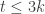 of tokens remaining among the players (i.e., not in the center pot). Hashing weak compositions of
of tokens remaining among the players (i.e., not in the center pot). Hashing weak compositions of  with
with  -subsets of
-subsets of 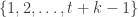 .
.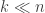 .
. of race outcomes for any number
of race outcomes for any number 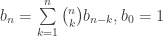
 runners, or worse, to more than
runners, or worse, to more than  medal types (i.e., steps on the podium), seems daunting.
medal types (i.e., steps on the podium), seems daunting. counting the number of such podiums:
counting the number of such podiums:
 if
if  or
or  … or answering the other variants with the same recurrence, but with different initial conditions.
… or answering the other variants with the same recurrence, but with different initial conditions. of random selections with replacement from a set of
of random selections with replacement from a set of 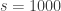 coupons that are needed to obtain at least one of every coupon in the set? This post collects solutions to some variants of this problem involving what Stadje [3] refers to as “group drawings,” where each random selection is not of a single coupon, but of a group of
coupons that are needed to obtain at least one of every coupon in the set? This post collects solutions to some variants of this problem involving what Stadje [3] refers to as “group drawings,” where each random selection is not of a single coupon, but of a group of  coupons. Python code implementing the formulas described here is available on
coupons. Python code implementing the formulas described here is available on  distinct coupon types, i.e., sampling the
distinct coupon types, i.e., sampling the 


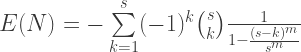
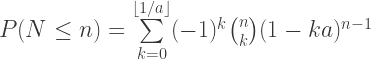
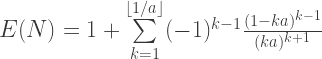
 is the length of each arc as a fraction of the circumference.
is the length of each arc as a fraction of the circumference.
 specified distinct intervals in
specified distinct intervals in ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) to
to ![[j]](https://s0.wp.com/latex.php?latex=%5Bj%5D&bg=ffffff&fg=333333&s=0&c=20201002) ), and the second inner summation is the discrete analog to the continuous case summation above, counting ways to “cover” the entire cycle of
), and the second inner summation is the discrete analog to the continuous case summation above, counting ways to “cover” the entire cycle of  .
.
 and
and  . The following Python code computes their intersection as another interval:
. The following Python code computes their intersection as another interval: made by its bounding radii relative to some zero reference… but we need some convention to deal with angle intervals that may contain that zero reference direction, as shown in the figure below.
made by its bounding radii relative to some zero reference… but we need some convention to deal with angle intervals that may contain that zero reference direction, as shown in the figure below.
 , so that the interval “sweeps counterclockwise” from direction
, so that the interval “sweeps counterclockwise” from direction  , through angle
, through angle  , to direction
, to direction  . And we can make such a representation unique if we “normalize” the bounding angles to enforce
. And we can make such a representation unique if we “normalize” the bounding angles to enforce  (so that
(so that 
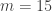 rows and
rows and 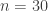 columns, in which
columns, in which 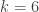 balls have been placed in distinct randomly selected bins. At each turn, both players simultaneously choose a bin to inspect. The first player to find a ball wins the game. (If both players choose the same bin containing a ball, the game ends in a draw.)
balls have been placed in distinct randomly selected bins. At each turn, both players simultaneously choose a bin to inspect. The first player to find a ball wins the game. (If both players choose the same bin containing a ball, the game ends in a draw.) columns? What if
columns? What if 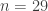 ?
?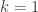 ball, this intuition is correct; neither player has an advantage for any size grid.) While at the same time, it is an undergraduate-level problem to reasonably efficiently compute the
ball, this intuition is correct; neither player has an advantage for any size grid.) While at the same time, it is an undergraduate-level problem to reasonably efficiently compute the  , Alice is at a very slight disadvantage, with an expected return
, Alice is at a very slight disadvantage, with an expected return 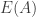 on a unit wager of approximately -0.000274524, or -0.027%. But for most “wide” grids with more columns than rows, Alice has the advantage: intuitively, Alice spends more time exploring new territory, while Bob has to waste more turns on bins that Alice has already searched.
on a unit wager of approximately -0.000274524, or -0.027%. But for most “wide” grids with more columns than rows, Alice has the advantage: intuitively, Alice spends more time exploring new territory, while Bob has to waste more turns on bins that Alice has already searched.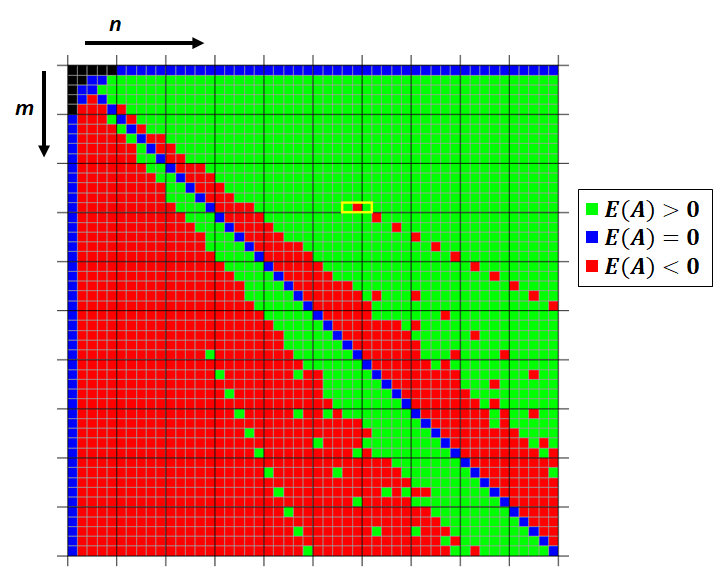
 with
with  of
of 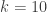 positive integers each at most
positive integers each at most  , there exist two distinct subsets of
, there exist two distinct subsets of  , the subsets
, the subsets  and
and 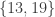 both have the same sum of 32.
both have the same sum of 32. subsets; how many possible sums are there? The empty set has sum zero, and the set
subsets; how many possible sums are there? The empty set has sum zero, and the set 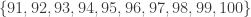 has the largest possible sum 955, for a total of
has the largest possible sum 955, for a total of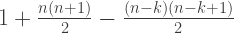
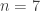 and
and 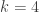 ; then by the above reasoning, given any set
; then by the above reasoning, given any set  , there are
, there are  subsets of
subsets of 
 is a counterexample, since all 16 of its subsets have distinct sums.
is a counterexample, since all 16 of its subsets have distinct sums. that we can vary. Let
that we can vary. Let  be the predicate asserting that every set
be the predicate asserting that every set  is true, and that
is true, and that  is false.
is false.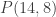 is true, using the pigeonhole principle as above: there are
is true, using the pigeonhole principle as above: there are  possible subsets, and only 85 possible sums from zero to 7+8+9+10+11+12+13+14=84.
possible subsets, and only 85 possible sums from zero to 7+8+9+10+11+12+13+14=84.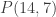 is also true.
is also true. ? Here, the same pigeonhole argument doesn’t work: there are only
? Here, the same pigeonhole argument doesn’t work: there are only 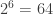 pigeons, but 70 available pigeonholes with sum labels from zero to 9+10+11+12+13+14=69.
pigeons, but 70 available pigeonholes with sum labels from zero to 9+10+11+12+13+14=69. , or
, or  , etc.
, etc.